本研究认为作为产业集聚,其“根植性”是必须的,基于此,本研究将油气产业集聚界定为油气资源勘探开发或加工企业以取得规模经济、节约成本而在特定地域集聚。由上可知,油气产业集群除了关注地理集聚性,还要考察产业链发育状况。......
2023-11-27
二、产业集群识别方法及其运用
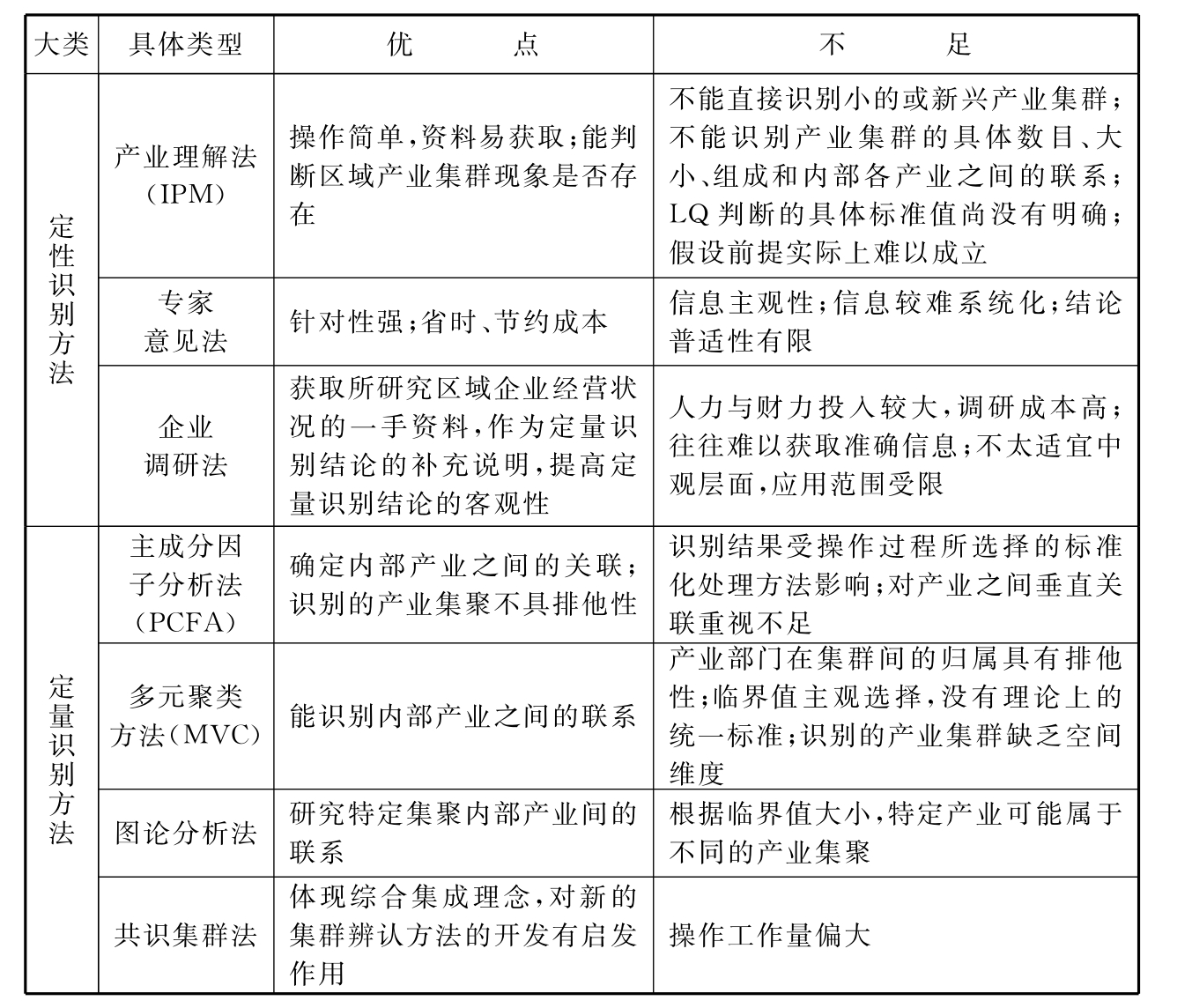
学术界从20世纪60年代以来发展了许多辨认产业集群的方法,如基于投入产出表的图谱分析和主成分因子分析、基于产业空间分布的空间联系与空间相关分析和区位熵法等[123]。王今、楚波等、贺灿飞等对现有产业集群识别方法进行了不同程度的综述,认为这些方法总体可分为定性识别方法和定量识别方法,并总结了各种方法的特点、优点和不足(表4-4)[124,120,123]。
表4-4 产业集群主要识别方法的优点与不足
资料来源:据王今[124]、楚波等[120]、贺灿飞等[123]归纳整理。(www.chuimin.cn)
在表4-4所示的方法中,产业理解法的区位熵(LQ系数)是该方法的核心,受到学者们的关注,也在实践中得到较广泛的运用。LQ系数计算公式为:
![]()
其中,Eij表示i产业j地区的就业、企业数或产值总数,LQij表达一个给定区域j产业i的就业、企业数或产值占有的份额与该产业的就业、企业数或产值在整个经济(如一个国家)中占有的份额之比,根据计算时所依据的指标是就业人数、企业数量还是产值,LQij相应有就业区位熵、企业数量区位熵和产值区位熵。通常认为LQij值大于1,表示i产业在给定j区域相对专业化,对j区域经济发展有重要作用,通常在j区域可能形成产业集群。由上述公式可以看出,区位熵计算仅涉及产业和区域数据,容易获取,容易理解,计算操作简便,因而在实践中受到较广泛的运用。主成分因子分析法、多元聚类法和图论分析法等定量方法则在区域产业集群现象存在的前提下,识别产业集群的数目、组成、内部关系等,因而能够比较深入地勾勒出集群的边界,但这些定量方法操作比较复杂,对数据要求也高,在我国目前集群数据统计系统尚不完善的前提下很难顺利实施;此外,产业集群识别中还需要考虑产业集群的两大特征——产业关联性和空间临近性。由此看来,产业集群识别也是复杂的。
在各识别方法的应用中,尽管区位熵法有其不足,但由于区位熵计算数据容易获取,计算也简便,因而在一般识别中,区位熵及它与其他指标组合的识别方法被较多学者[125~128]所采用,不过在区位熵系数的具体选择或判断标准上,不同学者的观点存在差异,如选择以雇员数计算就业LQ并取该指标大于1识别产业集群[125];将就业区位熵LQ和企业数一起作为判断产业集群的标准,并选择四位数产业就业区位熵不小于3和产业企业数目不小于100来辨认浙江省制造业产业集群[126];选择就业区位熵和产值区位熵的组合及创新能力识别旅游业产业集群[127]。看来,LQ判断标准值存在差异,那么,到底LQ达到多大才表示存在产业集群现象?至今尚未达成一致。Nauwelaers认为大于1.12就表明高水平的专业化,特别是一个集群在区域经济的份额达到20%时即被认为是“亮点”[129];有些研究则选择大于3[130~132]。本研究认为识别产业集群的LQ判断值存在行业差异,应视所研究行业的相关特征而定,另外,还应综合考虑3类LQ值,因为3类LQ值分别从3个不同侧面反映产业集群发育状况。除区位熵在实践中被较广泛地采用,因子分析方法也在产业集群识别中得到一定的运用,如被用来识别美国大都市区的产业集群[133,134]、加拿大安大略省的产业集群[135]以及北京市的产业集群[136],并得到了较理想的结果。由于各种产业集群识别方法各有优劣,于是有些学者在实际运用中寻求方法的组合,如Rey等融合主成分分析法和多元统计聚类法[137],梁进社等人综合运用主成分分析法和Czamanski法(2)对北京产业集群进行识别[138],李广志等综合应用区位系数法和主成分分析法对陕西省产业集群进行了识别与选择[128]。就区位熵3类指数之间的组合来看,企业数量区位熵与产业产值区位熵的组合[5]、就业区位熵与产值区位熵的组合[127]等组合识别法也已在实践中得到使用,但区位熵3类指数全面组合进行产业集群的识别在目前文献中极少见及,具体到油气产业集群则尚未见及。
有关 油气资源产业集群竞争力形成机理研究的文章

本研究认为作为产业集聚,其“根植性”是必须的,基于此,本研究将油气产业集聚界定为油气资源勘探开发或加工企业以取得规模经济、节约成本而在特定地域集聚。由上可知,油气产业集群除了关注地理集聚性,还要考察产业链发育状况。......
2023-11-27
由此看来,以上油气产业集群竞争力内涵界定从竞争力的要素、结构和能力三方面对油气集群竞争力作了较全面的揭示,同时又融入了整合的思想。具体到本研究油气集群竞争力层面,其相对性则表现为油气企业以集群形式发展时,相对于分散状态所具有的集群整体层面的竞争力。......
2023-11-27

尽管Porter在《国家竞争优势》一书中提到:产业集群的竞争力,大于各个部分加起来的总和,在产业集群中,有竞争力的产业提升另一个产业是正常趋势,它的扩张方向是由产业集群内部普及到全国[22]。......
2023-11-27

一是按产业集群内部企业之间的产业链关系划分,产业集群可以划分为垂直集群和水平集群,Porter认为垂直集群中的企业沿着产业链形成纵向的买卖关系,水平集群中的企业则具有共同的最终产品市场、使用共同的技术或劳动力技能及类似的自然资源,这两类集群都对集群的创新能力产生作用[22]。......
2023-11-27

因而,这些配套产业也应纳入到油气集群价值链之中,成为其中的一部分。图6-1油气资源产业集群价值链结构模型图6-1表明:第一,油气产业集群价值链由基础网络、辅助网络和配套产业构成,比集群价值链一般模型增加了“配套产业”,以上三部分构成一个有机的系统,最终实现油气集群竞争优势的培育。......
2023-11-27
这种资源整合观给集群竞争力形成机理的深入研究带来了有益的启示,但已有研究并未指出集群资源整合的格架。从本质上说,产业集群即是由价值链组成的有机网络系统[86]。......
2023-11-27
吴晓波等提出,除了基于RBV资源二分法划分的异质性资源和同质性资源外,集群资源还应包括存在于集群内部为集群企业所共享而对集群外部企业排斥的共享性资源,即集群竞争力资源划分为异质性资源、同质性资源和共享性资源[82]。以上资源及产业集群资源分类研究为油气资源产业集群资源要素分析提供了基础。......
2023-11-27

由此看来,产业集群竞争力和企业竞争力一样,其形成也需要资源整合的过程,即产业集群竞争力形成同样也符合RIBV。若对照企业资源整合观,产业集群资源整合观则可以描述为通过将集群所拥有的资源加以整合和合理配置,提高集群资源价值,从而创造集群竞争力。......
2023-11-27
相关推荐