3)英语原版教材词汇抽取中,也可考虑通过词库类别进行词汇抽取。对于一个存在于多个专业词典中的词汇,会被抽取多次,所以需要注意减少数据冗余,方便读者学习。......
2023-11-23
在本书第4章中对数字出版中的提供词汇提取的可行性进行了分析,包括技术可行性和词汇分布的可行性。
一个读者的外语水平越高,所认识的难词或者说低频词就越多。所以数字出版平台可以通过提供不同频段的词汇表来满足外语水平不同的读者需要。
词汇切分和抽取是自然语言处理技术的基础,尽管对于某些表意文字语言,如汉语,计算机自动分词的准确率还不能令人满意(大约90%)[5],实现精确的词频统计有些困难,但随着研究的发展和深入,不远的将来会使这一问题得到改进或解决。计算机运算速度的提高和云平台的兴起也为普及词汇抽取服务提供了良好的条件。各出版社可以利用云平台提供的软件实现服务功能,不用自己再单独设计和完成。然而,对于读者个体来说,即使外语水平大致相同,在细节方面也有不同,所以出版社平台提供的分段词汇表,无论采用何种抽取策略,都不可能完全满足读者需要。所以,下载后的词汇表应该能按页码、章节或字母顺序自由排序和筛选,并允许读者自由删除表中已经认识的词汇和保存修改后的结果。一个生词会在很多页中出现,有研究表明,学习者必须在一定时期内(如半年),接触同一个词7到10次才能记住。所以进行词频统计时,可允许每个单词对应7个不同的页码,至于其中的间隔,可以采取连续方式或根据书的具体情况,如页的多少而定。
1.供参考的词汇抽取策略
对于外文文学原著来说,可分为长篇和短篇,由于长篇在内容上的连贯性、短篇在内容上各自独立的分散性,所以采用的词汇抽取策略有些不同。
(1)长篇外文文学原著的词汇抽取策略
对于长篇文学作品,由于内容的连续性,读者是从前至后连续阅读的。同时,由于是一个作者所著,整本书的语言风格和词汇分布不会有大的变化。一本书本身是一个整体,所以可以通过对一本书整体进行词频统计,而形成不同频段的词汇表的方法进行词汇抽取。
第一,可采用直接对原著中词汇进行频率统计的方法。由于每本原著中的词汇量和词汇分布情况不同,可对数字平台上销售的每本书分别进行词频统计,形成对应该书的不同频段的词汇表,读者根据自己的需要下载这些词汇表。对于初中级外语水平的读者,从频率居前3000、4000开始至低频段的词汇较合适;对于语言水平较高的读者,可能频率居前7000到10000或15000到20000或更低频的单词是需要的。这种方法的优点是直接体现了原著内词汇的出现频率情况。但通过该方法抽取的词汇文件需要修订后才能提供给读者,因为有时候一些单词的难度和频率相关度不高,比如同形异义词和“问题词”(Problem Words)。
第二,可利用国际上语言研究成果,作为参考的抽取策略。以英语为例,美国当代英语词汇研究(Corpus of Contemporary American English)研究项目建立了4亿词汇的文献资料库,美国杨百翰大学对这个资料库用计算机方法筛选出了美语使用频率最高的100000个高频词汇和它的类词库[6]。词汇抽取可以该研究的词汇标准为参考,抽取出原著中对应于不同词频段的词汇,如以频率居前3000、4000直到20000或更低词频段;对于语言水平较高的读者,可直接从10000以上词频段开始。这种抽取方法与上述直接通过书内词汇频率统计方法获得的词汇表可能会有差异,但优点是从语言整体上而不是仅从原著本身体现词汇出现频率分布。对于汉语,可根据词频字典进行抽取。
第三,除了使用上述两种抽取策略,也可考虑通过不同的词库类别添加词汇所属词库标识。对于一门语言,有很多不同种类的测试和与其对应的词库。可按这些词库类别对各词频段的词汇添加标识,满足相应读者的需要。从心理学角度,对于一个计划参加托福考试的学生来说,会对词汇表中带有托福标识的词汇产生更强的记忆动机。新东方在线曾作出提示:多看英文名著有助于记忆GRE词汇,英文名著中有很多GRE词汇,利用情节进行GRE词汇记忆,同时也学会了这些GRE词汇的使用方法。荷马史诗《The Odyssey》(《奥德赛》)中的GRE词汇“libation”(另有一个翻译版本译作“drink-offering”)出现31次,另一个GRE词汇“suitor”,全书共出现多达233次。
第四,对于外文原著简写本,儿童读物等初级外语读物,可降低抽取词汇的起始词频段。如从500、1000等,满足读者要求。
(2)短篇外文文学原著的词汇抽取策略
对于中篇或短篇文学作品集来说,每一篇的内容都是独立的,有时是同一个作者的作品,但很多时候是多位作者作品的集合。每一篇不仅涉及的词汇较少,语言风格和词汇分布也不同。而读者也是以篇为单位进行阅读的,在某一篇作品中出现的词汇很可能不出现在其他篇内,所以不能采用通过对一本书整体进行词频统计的方法给出抽取词汇表,但可采用上面抽取策略中第二、三种,即语言研究成果或词频字典、词库的方法实现词汇抽取,同样对于简写本,需降低抽取词汇的起始词频段。实施抽取时,需要以每篇作品为独立单位,为每篇作品按照词频抽取出属于各词频段的词汇,形成包括释义、页码、词频字段且可按页码、词频进行筛选的对应每篇文章的普通词汇表。
2.外文文学原著词汇抽取流程图(见图5-1)
3.词汇表呈现
对抽取的词汇表,为方便读者下载,可参考表5-1、表5-2所呈现的方式。
4.词汇抽取中注意事项(www.chuimin.cn)
在上面的词汇抽取实施中,需要注意下面几个问题:
1)由于测试用词库的词汇量相对较少,除非是为了读者特定的兴趣,如要参加某种级别的语言考试服务,一般还是采取基于词频统计的方法实现完整的词汇分布抽取,提供符合不同读者需要的词汇表。所以,如果需要可以分别提供基于词频统计和测试词库的词汇表,供需要的读者下载。
2)如果在抽取的词汇表中含有音标和单词朗读,则能更全面地帮助读者改进和提高外语水平。对于为儿童读物抽取的词汇表,还可通过添加动画图片、增大字体显示等方法增加吸引力,引导阅读。
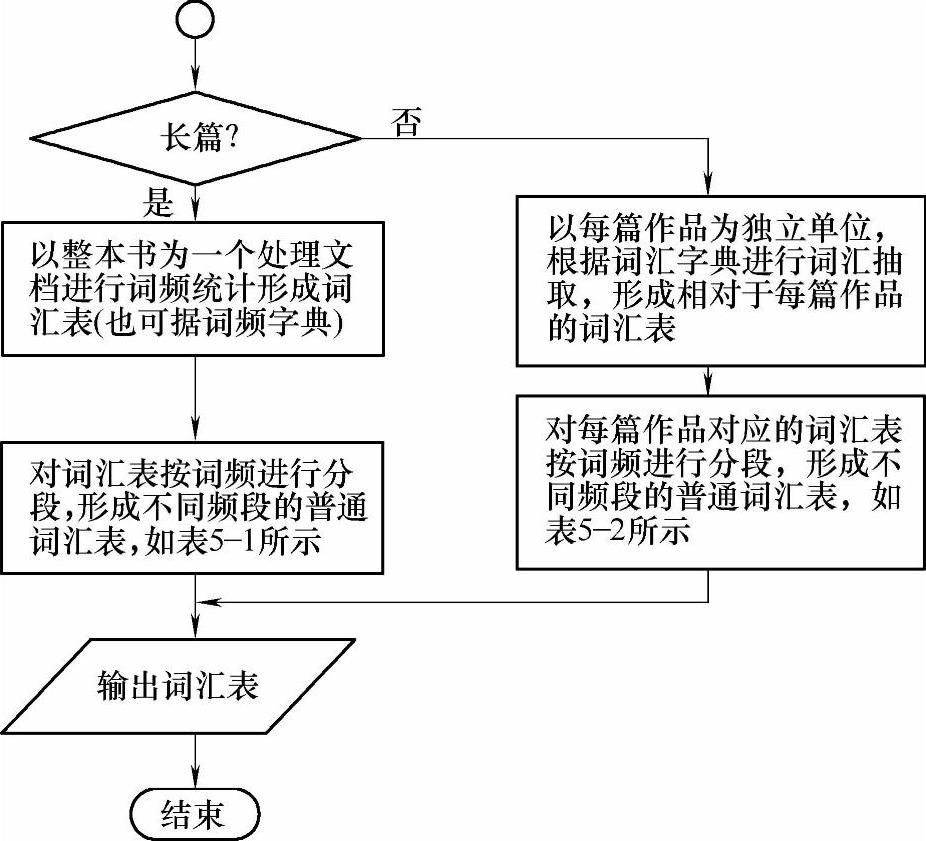
图5-1 外文文学原著词汇抽取流程图
注:对外文文学原著进行词汇抽取可采用多种策略,这里只给出了分别对应长篇和短篇词汇抽取的一种策略的流程图。
表5-1 长篇文学原著词汇表下载呈现

表5-2 短篇文学原著词汇表下载呈现
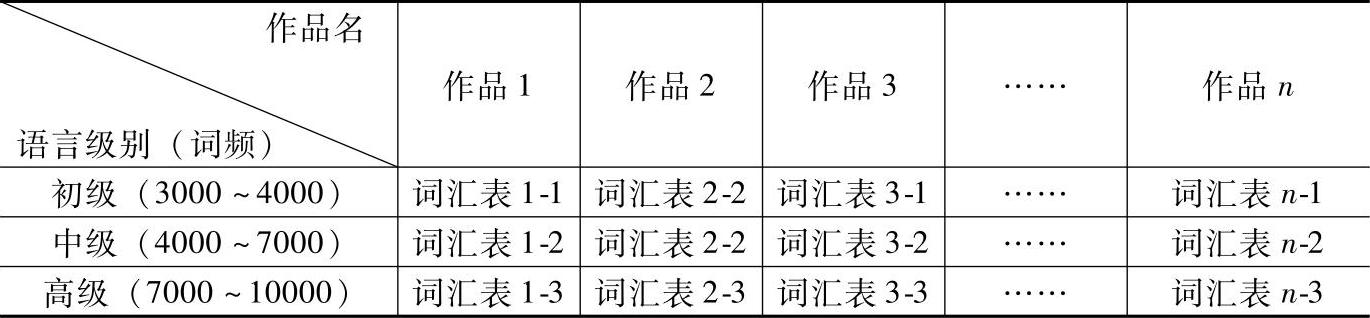
注:1.由于一本书中常用词占了大多数的原因,实际抽取的生词数量会非常有限,再经过频段划分,不会在数量上使读者产生负担感。
2.对于语言水平低的读者,可以先下载对应初级和中级的词汇表,待随着对内容的熟悉、词汇和语法知识也进步后,再尝试记忆对应于高级语言水平的词汇。
3)出版社平台可以按电子阅读的读者语言水平级别分类,收集读者在某些书籍的电子阅读中选定的词汇抽取信息,进行分析和归纳整理,形成经验数据文件,用于改进抽取策略和提供给对应纸质书的读者参考。
4)虽然词汇和难句提取服务能对读者的阅读提供帮助,但内容和文本难度仍然是外文文学阅读能否成功的重要因素,出版社平台应提供外文书籍的内容和阅读难度分级信息。
5)外文原著篇幅长、词汇量大,并由于是文学作品,生僻文字多,在词汇量不足的情况下不建议直接进行原著阅读,可以从原著的英语简写本着手,待词汇量和语法知识积累到一定程度再读原著。对于长篇外文原著的简写本,由于词汇量相对较少,提供的词汇表的起始词频值可根据具体情况确定。
6)对于各种外文名著、母语文学作品和专业文献中实施词汇抽取的词频起始值和最低频值的确定还需要语言学家的调查研究,这里给出的只是参考值。

3)英语原版教材词汇抽取中,也可考虑通过词库类别进行词汇抽取。对于一个存在于多个专业词典中的词汇,会被抽取多次,所以需要注意减少数据冗余,方便读者学习。......
2023-11-23

从人类的认知过程来看,印刷文本为线性文本,可呈现连续的信息流。如果能对一本电子书中的词汇进行某些统计处理和分析,把相应的词汇及其解释抽取出来形成词汇表文件供下载。......
2023-11-23

而数字出版、自然语言处理技术和云计算的出现,可以帮助我们实现这个愿望,即通过数字出版提供词汇和难句抽取服务。本节探讨了基于数字出版平台的外文文学原著出版中普及词汇抽取服务的问题,同时希望该探索能对促进各种现代技术在数字出版方面的应用产生积极影响。......
2023-11-23
普通词汇的抽取是依据语言词汇使用分布的规律,即一本书包含很多词汇,但常用单词占了绝大部分。通过直接对作品中词汇进行频率统计的方法实现词汇抽取的优点是直接体现了原著内词汇的频率分布情况。......
2023-11-23

期刊文献是人们进行科学交流的重要工具,对于促进人类社会的发展具有重要意义。世界各国为科研和学术交流的需要,都购买了国际主流科技期刊一些数据库的使用权。为此,本节探讨了在数字期刊出版平台应用自然语言处理技术,为期刊文献提供词汇抽取服务,帮助读者更有效和容易地阅读外文参考文献的问题。......
2023-11-23

outlet/atlet,atlt/联想:短语let outn.①出口;出路waste air outlet 废气出口②发泄途径 Levin described rap as a lawful expression of street culture, which deserves an outlet.莱文把说唱音乐描述成街头文化的一种合法表达方式,而街头文化应该有自己的表现途径。stationary/stenri/联想:station(车站)+ary(……的)→车站应是固定的,而不是移来移去的→固定的a.固定的;静止不动的 From an analysis of the hot spot population it appears that the African plate is stationary.从热点地区的人口情况分析来看,非洲板块似乎是静止不动的。......
2023-10-13

hawk/hk/联想:鹰的喙很像钩子vt.①叫卖;兜售②散布消息n.鹰;鹰派人物hawk sth.about/around 沿街叫卖某物watch sb. like a hawk 仔细打量某人curious/kjris/词根:curi(关心)+ous(……②奇特的;稀奇的 Something curious has been happened in American universities.美国的大学中发生了一件稀奇古怪的事。curiously ad.好奇地delicate/delkt/联想:这表明他们之间的关系很微妙a.①易碎的;纤弱的②微妙的 Parents still have a major role to play, but now it is more delicate.家长仍然起主要作用,但这时的作用更加微妙。......
2023-10-13

当产生明渠均匀流条件不能满足,或者在河渠中修建人工建筑物时,都将引起非均匀流动。在明渠非均匀流中,若流线的曲率半径很大,各流线接近于互相平行的直线,这种水流称为明渠非均匀渐变流,反之为明渠非均匀急变流。在自然界的河流中最多见的是明渠非均匀流,如因自然地形而形成水跃、水跌、壅水旋涡等。......
2023-11-20
相关推荐