《软件研发成本度量规范》标准适用于度量成本与功能规模密切相关的软件研发项目的成本。《规范》中的规模估算可依据其中任一方法识别功能点计数项,并根据其对应的权值计算出软件功能规模。总之,《规范》在软件行业的应用,将带来软件行业甲乙双方双赢的结果,可以维护市场健康有序发展。《规范》的应用,将为乙方在甲乙双方谈判中提供有利的谈判筹码。......
2023-11-19
1.基本流程与原则
【标准原文】
图2展示了成本估算的基本流程。在依据此流程进行软件研发成本估算时应考虑以下情况:
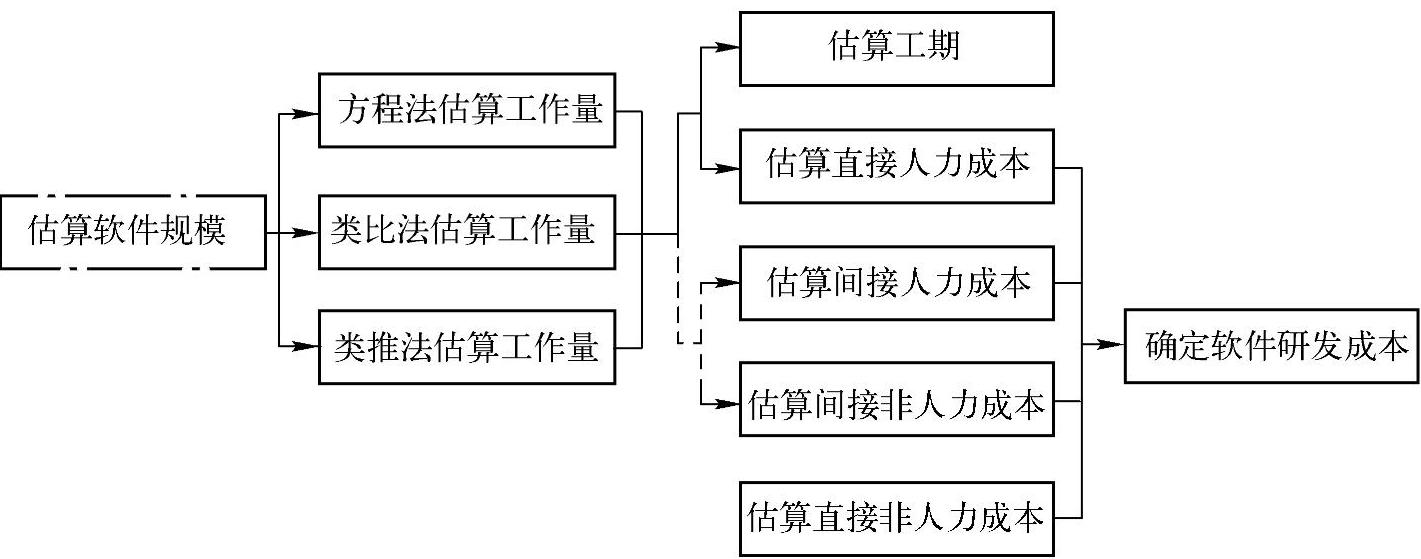
图2 软件研发成本估算基本流程
——在需求极其模糊或不确定时,宜采用类比法或类推法,直接粗略估算工作量和工期,也可直接粗略估算成本;
——对于有明确工期要求的项目,在采用方程法估算工作量时,工期要求有可能是方程的参数之一;
——间接成本是否与工作量估算结果相关取决于间接成本分摊计算方式;
——工期估算结果与直接人力成本估算结果及其他成本估算结果相互关联并可能互相影响。如工期估算的结果有可能导致重新估算工作量和直接非人力成本,并最终改变软件研发成本估算结果。
在成本估算过程中,应遵循以下原则:
a)充分利用基准数据,采用方程法、类比法或类推法,对工作量、工期、成本进行估算。对于进行规模估算的项目,宜采用方程法估算工作量、工期和成本;
b)在规模估算时,应根据项目特点和需求的详细程度选择合适的估算方法;
c)工作量、工期、成本的估算结果宜为一个范围而不是单一的值;
d)成本估算过程中宜采用不同的方法分别估算并进行交叉验证。如果不同方法的估算结果产生较大差异,可采用专家评审方法确定估算结果,也可使用较简单的加权平均方法。
【标准释义】
软件研发过程的特殊性决定了软件研发成本的估算方法,既不同于制造业产品的成本估算方法,也不同于建设项目的财务评价方法。为指导软件研发相关方进行科学统一的估算,在本标准中,软件研发成本估算过程可进一步细分为估算规模、估算工作量、估算工期和估算成本等四个过程,其中成本估算需要对直接人力成本、间接人力成本、间接非人力成本及直接非人力成本分别进行估算。
本标准中的四个估算过程,层层递进,逐步细化,最终达到科学、一致的成本估算。在软件研发成本估算的每个过程中,相关人员应依据《软件研发成本度量规范》标准,结合项目实际情况,执行研发成本度量的过程,并遵循一定的原则,选择适当的估算方法。以下对四个估算过程分别给予说明。
(1)估算规模
通常情况下,规模估算是软件成本估算过程的起点。估算规模是后续计算软件项目的工作量、成本和进度的主要依据,是项目范围管理的关键,因此,在条件允许的情况下,应进行规模估算。在规模估算过程中,需要注意以下情况:
a)在规模估算开始前,应根据可行性研究报告或类似文档明确项目需求及系统边界。项目需求除包含最基本的业务需求外,还应进行初步的子系统/模块划分,并对每一子系统或模块的基本用户需求进行说明,以保证可以根据项目需求进行规模预估。
b)依据项目特点和需求详细程度不同,通常估算人员在选择估算方法时应采用纳入国际标准的功能点方法进行功能规模估算,如COSMIC-FFP方法、IFPUG方法、MkⅡ方法、NESMA方法及FiSMA方法。
c)若当前的项目需求极其模糊或不确定,可不进行规模估算,而直接采用类比法或类推法估算工作量、工期和成本。
(2)估算工作量
在完成规模估算后,应当开展工作量估算工作,若当前项目未开展规模估算,也可直接启动工作量估算工作。工作量估算时,可采用方程法、类比法和类推法。
方程法:即基于基准数据建立参数模型,通过输入各项参数,确定估算值。
类比法:即将待估算项目的部分属性与类似的一组基准数据进行比对,进而确定估算值。
类推法:即将待估算项目的部分属性与高度类似的一个或几个已完成项目的数据进行比对,并进行适当调整后确定估算值。
在开展工作量估算的过程中,需要注意以下情况:
a)当需求极其模糊或不确定时,如果此时具有高度类似的历史项目,则可直接采用类推法,充分利用历史项目数据来粗略估算工作量。
b)当需求极其模糊或不确定时,如果此时具有与本项目部分属性类似的一组基准数据,则可直接采用类比法,充分利用基准数据来粗略估算工作量。
c)对于规模估算已经开展的项目,可采用方程法,通过输入各项参数,确定待估算项目的工作量。若客户或高层对项目的工期有明确的要求时,在采用方程法估算工作量时,工期要求有可能是方程的参数之一。
d)为追求估算的准确性,建议在条件允许的情况下,采用两种估算方法,对估算结果进行交叉验证。若估算结果差别不大,可直接使用两种估算结果的平均值或以某种估算结果为准,若差别较大,需进行差异分析。
e)工作量的估算结果宜为一个范围,而不是单一的值。
(3)估算工期
在工作量估算结束后可根据工作量,采用科学的方法进行工期估算过程。在估算工期的过程中,需要注意的情况是:
a)类推法、类比法、方程法同样适用于工期估算。
b)工期估算的结果有可能导致重新估算工作量。比如,当工期估算结果长于期望工期时,压缩工期会增加项目工作量。
c)工期估算结果与直接人力成本估算及其他成本估算结果相互关联并可能相互影响,可能导致重新估算直接非人力成本,从而最终改变软件研发成本估算结果。比如,为了满足工期要求,项目团队通常会加班,而由此产生的加班费和餐费等,会分别引起直接人力成本和直接非人力成本的增加。
d)工期的估算结果通常也是一个范围,而不是单一的值。
(4)估算成本
在获得了工作量和工期结果后,可采用科学的方法进行成本估算。在成本估算过程中,应需要注意的情况:
a)类比法和类推法,同样适用于需求极其模糊或不确定时的成本估算。
b)间接成本是否与工作量估算结果相关取决于间接成本分摊计算方式。在间接成本中,服务于研发管理整体需求的非项目人员的间接人力成本的分摊计算方式就直接关系到工作量估算结果,比如部门经理、项目管理办公室(PMO)、工程过程组(EPG)人员等的成本。而不为某个特定项目而产生的服务于整体研发活动的间接非人力成本的分摊计算方式就与工作量估算结果无关。
c)成本估算结果,也通常为一个范围,而不是单一的值。
在软件研发成本估算过程中,相关人员还需要注意:
a)基准数据:在采用方程法、类比法或类推法对工作量、工期和成本进行估算的过程中,应充分利用基准数据。
——对于委托方和第三方,建议使用或参考行业基准数据(由北京软件造价评估技术创新联盟每年发布的年度软件行业基准数据分析报告是基于CSBMK基准数据库的数据分析结果,该基准数据库是当前国内规模最大的数据库。截至2016年10月,包括国际、国内项目数据超过6759套)进行估算。估算模型的调整因子的增减或取值有可能随着行业基准数据的变化而变化。
——对于开发方,在引入行业基准数据的基础上,可逐步建立组织级基准数据库,以提高估算精度。组织级基准数据定义应与行业基准数据定义保持一致,以便于与行业基准数据进行比对分析,并持续提升组织能力。
b)交叉验证:为提高估算结果的准确性和科学性,通常在规模、工作量、工期和成本的估算过程中,可以选择类比法、类推法或方程法等多种不同的方法对项目分别进行估算,并将多个方法的估算结果进行交叉比对分析,从而对估算结果进行验证。如果不同方法的估算结果差异不大,则说明当前项目的估算结果是可用的,可直接使用或者使用平均值作为估算结果。如果不同方法的估算结果差异较大,可进一步分析和调查差异产生的原因,并通过专家评审法和加权平均法对差异情况做进一步处理,从而获得最终的估算结果。
2.估算软件规模
【标准原文】
在规模估算前,应根据项目范围明确系统边界。对于尚未确定的需求,应该在规模估算前确定估算原则。
估算人员应根据已确定的系统边界和需求描述估算软件规模。
规模估算所采用的方法,应根据项目特点和估算需求,选用国际标准化组织ISO/IEC已发布的以下五种规模度量标准中的一种,即:
a)ISO/IEC 19761(COSMIC-FFP方法);
b)ISO/IEC 20926(IFPUG方法);
c)ISO/IEC 20968(MkⅡ方法);
d)ISO/IEC 24570(NESMA方法);
e)ISO/IEC 29881(FiSMA方法)。
在规模估算时,应考虑可能的需求变更程度,并对规模估算结果进行适当调整。
注:根据相关国际标准中的方法适用范围声明,COSMIC方法适用于商业应用软件和实时系统;IFPUG方法适用于所有类型软件的功能规模度量;MkⅡ方法适用于逻辑事务能被确定的任何软件类型;NESMA方法与IFPUG方法非常类似,但对功能点计数进行了分级,以便在估算的不同时期选择不同精度的方法进行估算;FiSMA方法适用于所有类型软件的功能规模度量。
【标准释义】
(1)在规模估算前,应根据项目范围明确系统边界。系统边界包含如下含义:
a)用于划分系统与其他系统,特别是相邻系统关系的一种方法,将项目分割成系统内和系统外,系统内属于项目创建内容,系统外不需要创建,但需要考虑它们之间的接口;
b)应说明哪些元素是属于系统内,哪些元素属于系统外部环境;
c)除了能确定系统内元素外,还应界定本系统对外的输入与输出,即本系统与外部环境的关系。
(2)对于尚未确定的需求,应该在规模估算前根据项目具体特点和商务因素确定估算原则。
估算人员应根据已确定的系统边界、需求描述、项目特点等,从国际标准化组织ISO/IEC已发布的以下五种功能规模度量标准中选择合适的标准估算软件功能规模:
a)ISO/IEC 19761(COSMIC-FFP方法);
b)ISO/IEC 20926(IFPUG方法);
c)ISO/IEC 20968(MkⅡ方法);
d)ISO/IEC 24570(NESMA方法);
e)ISO/IEC 29881(FiSMA方法)。
以上这五种功能点度量方法的计算规则各不相同,在应用上也各有特点。表2-2和表2-3中则分别从技术角度、用户角度对这五种功能点方法进行了多维比较。
表2-2 功能点方法比较(技术角度)
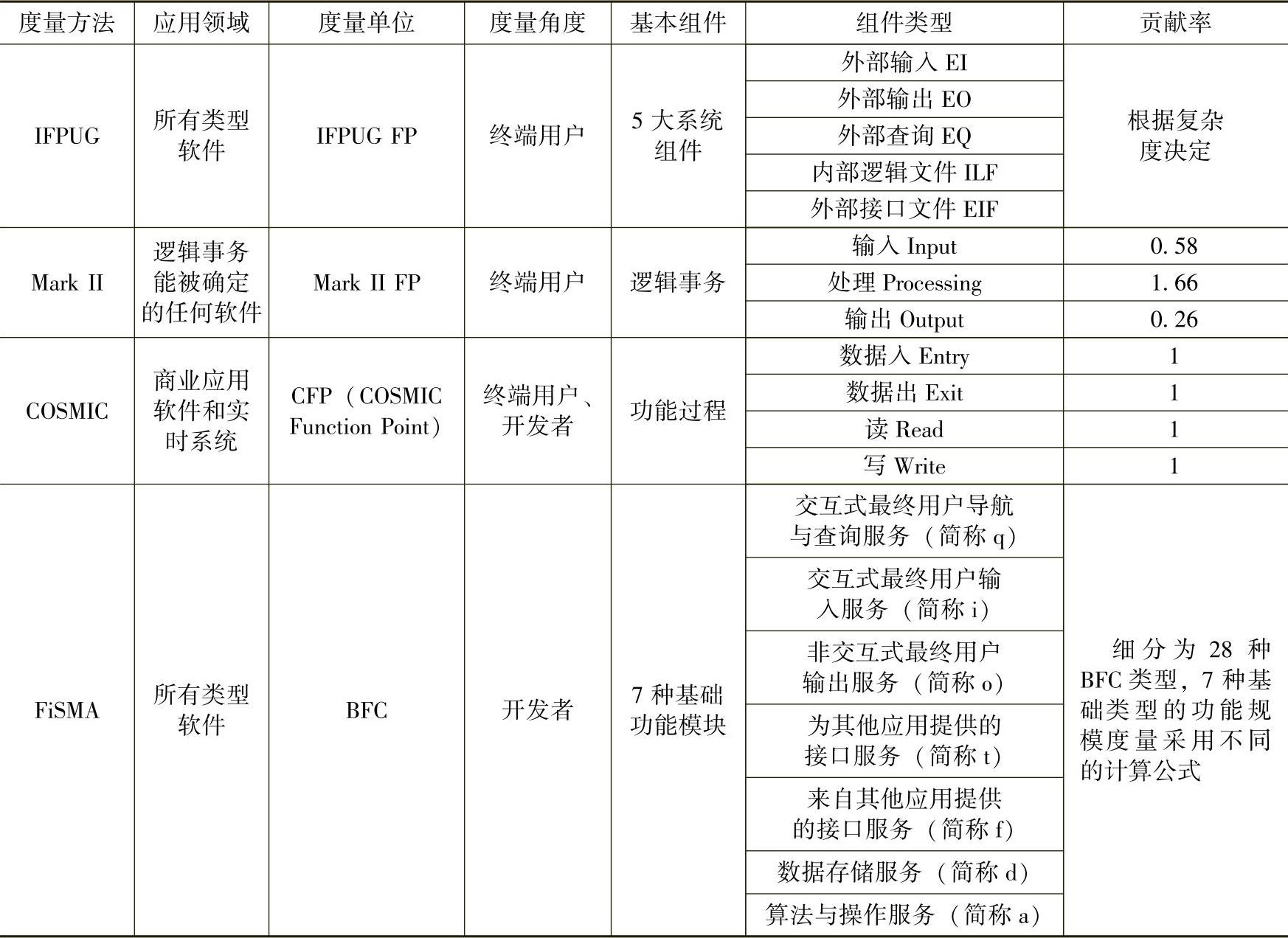
表2-3 功能点方法比较(用户角度)

可以看出NESMA功能点方法不但易学易用、快速、经济,而且容易开发和建立用户自己特有的估算模型。NESMA方法完全兼容于IFPUG方法,没有引入任何新的概念,在五种国际标准中,只有NESMA方法定义了3种应用场景以支持不同粒度的估算,并且随着项目的进展和需求的完善,估算者可以不断修正之前的结果,进行持续的软件度量。因此如果使用行业标准进行早期估算(如编制预算、招投标),应采用NESMA方法中的预估功能点或估算功能点方法。当然NESMA方法针对不同项目的实际操作性不一定完全适用,在估算上也存在一些主观性,它本身也在不断演化过程中,组织可以不断地进行定制和裁剪,只要采用统一的计数和计算标准,就可以很好地运用。
目前,五种功能规模度量标准中,IFPUG和NESMA方法是国际主流应用标准,约占90%以上。下面着重介绍IFPUG方法的基本概念和NESM方法的分级场景。
(3)IFPUG中功能点计数项包括以下5个:
a)内部逻辑文件(Internal Logical File,ILF,简称内部数据)
软件内部需要维护(如增删改查)的数据。
b)外部接口文件(External Interface File,EIF,简称外部接口)
在其他系统中维护但本软件需要调用的数据。
c)外部输入(External Input,EI)
向软件输入数据或发送指令。
d)外部输出(External Output,EO)
软件向使用者或其他系统输出的数据或发送的指令。
e)外部查询(External Query,EQ)
EQ指使用软件进行的简单查询。
功能点计数项分为数据功能和交易功能两类,以下分别加以说明。
1)数据功能代表系统提供给用户的满足系统内部和外部数据需求的功能,分为内部逻辑文件(ILF)、外部接口文件(EIF)两类。
逻辑文件不是传统数据处理意义上的文件,也不是实现意义上的物理的数据集合,即它与具体实现时设计出来的物理模型是无关的。逻辑文件是指一组用户可识别的、逻辑上相互关联的数据或者控制信息,对逻辑文件的操作为业务需求引起,用户可以理解并识别。
①识别逻辑文件的步骤如下:
a)识别业务对象或业务规则。业务对象应该是用户可以理解和识别的。业务对象包括业务数据或业务规则,如“企业黑名单”、“黑名单生成规则”等。而一些为了程序处理而维护的数据则属于编码数据,如国家/地区信息表。所有的编码数据均不识别为逻辑文件,与之相关的操作也不识别为基本过程;
b)确定逻辑文件数量。需要根据业务上的逻辑差异及从属关系确定逻辑文件的数量。例如,对于人力资源管理中的“员工信息”,虽然“固定期限合同员工”与“无期限合同员工”的信息有所差异,但其维护方式基本一致,因此不识别为不同的逻辑文件;而对于公文管理中“收文信息”和“发文信息”,虽然物理特征类似,但这两类信息有完全不同的业务行业,与其相关的业务操作也不相同,因此可识别为不同的逻辑文件。
c)是否是ILF。即确定该逻辑文件是否在本系统内进行维护。如果是,则记为ILF;如果本系统仅为引用,而在其他系统维护,则为EIF。
d)任何逻辑文件在系统边界之内仅被计数一次,若有时是ILF,有时是EIF,则计数为ILF。
②逻辑文件符合如下简易识别规则:
a)ILF(内部逻辑文件)
——ILF指在待开发系统内部逻辑上的一组数据;
——用户可以理解和识别ILF,对ILF的操作是用户的业务需求。
示例:根据如下需求从“逻辑”性上识别ILF:
会议管理系统……包括X局(信息中心)处(或公司)举行的会议、会议计划、安排、记录、查询、通知、纪要等功能均实现电子化,提高会议效率。
从需求中识别的内部逻辑文件包括:会议信息、人员信息、单位信息。如会议纪要需要独立记录,如会议记录删除后会议纪要仍单独保留,则会议纪要也要识别为逻辑数据。
b)EIF(外部接口文件)
——EIF指由本系统引用(即“读”),在系统边界外由其他系统进行维护的逻辑上的一组数据;
——本系统的EIF一定是其他某系统的ILF。
2)交易功能代表提供给用户的处理数据的功能,每一个交易功能都是一个完整的基本过程,一个基本过程应该是业务上的原子操作,并产生基本的业务价值,基本过程必然穿越系统边界,基本过程分为EI、EO和EQ类。
①EI是处理来自系统边界之外的数据或控制信息的基本处理过程。其主要目的是维护一个或多个ILF或者改变系统的行为。对业务对象的增、删、改等操作通常都是EI。
EI的基本识别规则如下:
a)它是来自系统边界之外的输入数据或控制信息;
b)如果穿过边界的数据不是改变系统行为的控制信息,那么至少应维护一个ILF;
c)确保该EI没有被重复计数,即任何被分别计数的两个EI至少满足三个条件之一(涉及的ILF或EIF不同、涉及的数据元素不同或处理逻辑不同),否则被视为同一EI;
②EO是向系统边界之外发送数据或控制信息的基本处理过程,其主要目的是向用户呈现经过处理的信息,而不仅仅是在应用中提取数据或控制信息,对已有数据的统计分析、生成报表通常属于EO。
EO的基本识别规则如下:
a)将数据或控制信息发送出系统边界;
b)处理逻辑包含至少一个数学公式或计算过程;或者产生了衍生数据;或者维护了至少一个ILF;或者改变了系统的行为;
c)确保该EO没有被重复计数,即任何被分别计数的两个EO至少满足三个条件之一(涉及的ILF或EIF不同、涉及的数据元素不同或处理逻辑不同),否则被视为同一EO;
EQ是向系统边界之外发送数据或控制信息的基本处理过程,其主要目的是向用户呈现未经加工的已有信息。对业务数据的查询、已有信息的显示通常属于EQ。
③EQ的基本识别规则如下:
a)将数据或控制信息发送出系统边界;
b)处理逻辑可以包含筛选、分组或排序;
c)处理逻辑不可以包含数学公式或计算过程,不可以产生派生数据,不可以修改逻辑文件;也不可以改变系统行为,但可以对已有数据进行筛选、分组或排序;
d)确保该EQ没有被重复计数,即任何被分别计数的两个EQ至少满足三个条件之一(涉及的ILF或EIF不同、涉及的数据元素不同或处理逻辑不同),否则被视为同一EQ;
(4)相比IFPUG方法,NESMA方法更着重于项目早期的估算功能,针对IFPUG方法分析过程比较复杂,计算工作量大,估算成本高,不适合项目早期规模估算的不足,NESMA方法基于原有规则提出了两种快速计算的方法,共3种应用场景,在估算的不同时期可选择不同精度的方法进行估算。
NESMA方法3种应用场景如下:
a)预估功能点(简化一)
功能点规模统计只识别ILF和EIF文件,可用于预算或招投标阶段,采用如下公式计算:
功能点数≈35×ILF+15×EIF
这一公式基于如下假设:平均情况下,每个ILF对应3个EI、2个EO和1个EQ,每个EIF对应1个EO和1个EQ,35和15是将上述ILF、EIF、EI、EO、EQ的复杂度默认为中,再考虑系统整体的功能性得出的。
b)估算功能点(简化二)
功能点规模统计仍是5类基本功能组件的功能点数之和,采用如下公式计算:
功能点数=10×ILF+7×EIF+4×EI+5×EO+4×EQ
这一公式基于如下假设:将ILF、EIF、EI、EO、EQ的复杂度默认为中,其他步骤与IFPUG方法一样。
c)详细功能点
识别5类基本功能组件的功能点数,并根据复杂度决定取值后计算见表2-4。
表2-4 各类基本功能组件的功能点数参考值

NESMA的两种简化方法都是基于“默认”值来计算的,根据大量样本项目分析,此种计算结果与IFPUG方法得到的结果的平均值相近,但对个体项目,特别是小型项目常有较大差异。
在规模估算时,应考虑可能的需求变更程度,并对规模估算结果进行适当调整。据北京软件造价评估技术创新联盟统计数据,规模变更因子预算时取值为2,招标时取值为1.5,投标为1.26,项目计划为1.26,软件开发团队也可以根据具体情况进行调整,如根据组织内项目规模变更统计数据校正此数据。
随着软件复杂度越来越高,软件规模越来越大,对于非功能需求的度量也越来越迫切。非功能需求,指软件产品为满足业务需求而必须具有的,除功能需求以外的特性。非功能用户需求是描述软件如何实现功能而不是具备什么功能。非功能特性包括产品必须具备的质量属性和必须遵守的约束。例如:软件性能需求、软件安全性需求、软件可用性需求等。
相对于功能规模,非功能需求的规模更加难以度量。为了有效评估非功能规模对于项目资源代价的影响,行业内通常有两类处理方式:宏观方式和微观方式。宏观方式即不对非功能规模直接度量,而是以功能规模为基础,通过对基准数据的细分,确定特定类型软件的软件因素调整因子,进而估算项目所需的工作量、成本、工期,通过此种方式估算的结果,已包含此类软件通常所涉及的非功能要求对于项目资源的影响;微观方式则是对非功能规模直接度量,一般采用两种方式,一是可以通过对功能点方法进行定制,定量评估非功能规模。例如在金融行业,由于性能等方面的考虑,大量账务处理是通过后台批量程序定时完成的,通过对功能点方法适当定制,可以有效地对此类需求进行规模度量;二是引入专用的非功能规模度量方法(如SNAP),此类方法针对非功能规模提出了明确的评估规则,但由于方法产生较晚,相关行业实践及数据较少,在实际应用时,还需要开展相关分析工作以保证和功能规模数据有效结合,进而获得准确的估算结果。
3.估算工作量
(1)估算准备
【标准原文】
在进行工作量估算前,应:
a)对项目风险进行充分分析。风险分析时应考虑技术、管理、资源、商业多方面因素。例如:需求变更、外部协作、时间或成本约束、人力资源、系统架构、用户接口、外购或复用、采用新技术等。
b)对待实现功能复用情况进行分析,识别出复用的功能及可复用的程度。
c)根据经验或相关性分析结果,确定影响工作量的主要属性。
委托方应考虑的主要因素包括(但不限于):
1)软件规模;
2)应用领域,如委托方组织类型、软件业务领域、软件应用类型等;
3)质量要求,如可靠性、可使用性、效率、可维护性、可移植性等。
开发方除考虑以上因素外,还应考虑的因素包括(但不限于):
1)采用技术,如开发平台、编程语言、系统架构、操作系统等;
2)开发团队,如开发方组织类型、团队规模、人员能力等;
3)过程能力,如开发方过程成熟度水平、管理要求等。
d)选择合适的工作量估算方法。对于难以进行规模估算的项目,宜采用类比法或类推法;对于已经进行了规模估算的项目,宜采用方程法。
【标准释义】
估算准备:工作量是很多开发组织进行估算的主要对象。在本标准中,工作量所表达的含义是完成某个项目或系统开发所需的全部工作量,包括从项目立项开始到项目完成验收之间开发方的需求、设计、构建(包括编码、集成)、测试、实施及相关的项目管理、支持活动的工作量。
需求活动包括:需求调研、需求分析、原型开发、编制各种需求文档、需求评审、需求变更等活动;
设计活动包括:架构设计、技术方案选择、概要设计、详细设计、设计评审、设计变更等活动;
构建活动包括:编码、代码走查、集成等活动;
测试活动包括:测试计划、测试用例编写、测试用例评审、测试用例变更、测试环境准备及验证、单元测试、集成测试、系统测试等活动;
实施活动包括:用户支持文档编写及验证、验收测试、系统安装部署、用户培训等活动;
其他活动:是指在上述活动中没有包含的项目中的其他活动,例如项目管理、质量保证、配置管理、项目组内部培训、技术讨论及交流等活动。
在标准中,已明确指出项目成员包括参与该项目研发过程的所有研发或支持人员,如项目经理、需求分析人员、设计人员、开发人员、测试人员、部署人员、用户文档编写人员、质量保证人员、配置管理人员等。此处需要注意的是,项目组成员包括该项目的QA(质量保证人员)及配置管理人员,但不包括客户或用户。因此,项目组工作量的统计也不包括客户、用户或其他项目组外人员的工作量。
进行工作量的估算,是估算软件成本的基础。工作量与软件成本存在直接的联系。同时,开发组织内部也需要合理的工作量估算来进行项目计划,编制WBS等工作。
进行工作量之前,应从以下几个方面进行准备:
a)风险分析。风险分析是项目管理中的重要活动,其目的在于协助项目开发组织识别项目运行过程中的潜在问题,并提前采取措施。项目的风险可能来自许多方面,一般而言建议从技术、管理、资源、商业等角度进行考虑。在进行工作量估算之前进行风险分析,旨在使用风险分析所得结果对工作量估算的结果进行适当的调整。
一般的风险管理方法中,通常使用风险的发生概率与风险的影响程度的乘积作为风险系数,便于开展风险管理。在进行工作量估算前,同样可以使用该方法获得风险系数,从而对工作量进行调整。
例如采用方程法进行工作量的估算,可在方程中设置反映风险分析结果的参数,根据风险分析的结果对参数进行调整,从而影响工作量估算的结果。在类推法中,在找到高度相似的历史项目估算工作量时,也应根据风险分析的结果对估算结果进行适度的调整。
b)复用程度分析。在现代的软件开发过程中,为了提高效率和质量,大部分软件企业都会将某些通用功能转化为可重用功能,或者开发组织具备某方面项目的开发经验,遗留下了可以复用的组件,这些情况都可能降低开发所需的工作量。
对复用情况的分析原则,可以考虑从系统功能的复用度入手,结合功能点方法,对于每个逻辑文件的复用程度给出明确的定义和系数。可以应用在规模估算之后,在未调整规模的基础上首先进行复用程度的调整。
如表2-5所示,首先可对复用程度进行分级,并确定不同级别的复用程度与规模估算之间的系数。
例如,将复用程度分为三级,每个级别对应不同的系数。
表2-5 复用程度及对应系数

开发组织可以分析系统中不同功能组件的复用度,利用规模估算的结果乘以对应系数来对规模进行调整,从而间接实现对工作量的调整。
如何判断复用度,可以根据企业的实际情况出发,定义适合本组织的复用度:
以下为复用度定义示例:
对于ILF:
复用程度为1(高):现有的产品已经处理过这些数据,且EI/EO/EQ完全达到或超过需求。
复用程度为2(中):现有的产品处理过这些数据,但提供的EI/EO/EQ与需求有一定的差距。
复用程度为3(低):现有产品没有处理过类似的数据。
对于EIF:
复用程度为1(高):现有产品有公开的可调用的方法与类似接口集成。
复用程度为2(中):现有产品曾与类似接口集成过,但发生在编码级。
复用程度为3(低):现有产品从未与类似接口集成过。
从组织实际应用的角度出发,可以定义更多级别的复杂度,但需要考虑在判断复杂度方面所付出的成本。
c)考虑从软件和开发两方面因素来确定工作量的主要属性。软件因素可以被理解为待开发软件和系统本身所具有的特性,这些特性是客观存在的,不会随着不同的开发者而有不同。这些特性可以被直观地识别,也可以通过某些方法被识别。对于待开发系统或软件而言,这些特性更多地表现为一种约束,任何开发者进行开发时,都必须将软件因素作为一种约束条件考虑在内。典型的软件因素如下:(www.chuimin.cn)
规模:可以通过功能点方法来进行估算,并根据历史数据分析规模对生产率的影响。虽然传统的估算理论及模型认为随着项目规模的增加,项目复杂度变大,因而生产效率会有所降低。但根据北京软件造价评估技术创新联盟对国内外数据的分析结果,在通常的商业应用开发中(规模不超过10000FP),项目生产率会随着系统规模的增加而缓慢提高。
应用领域:主要对于委托方而言,其组织的类型(政府、银行、大型企业等),待开发项目的业务领域(金融、政务、生产制造等),应用类型(OA、ERP、MIS)等,都是可以直观识别的软件属性。
质量属性:一般指可靠性、可使用性、效率、可维护性、可移植性。开发组织应特别注意明确委托方对于质量的需求,并将其作为工作量调整的重要考虑因素。
开发因素更多的是由开发团队的特性决定的。不同的开发团队,因为自身特点不同,在完成同样的软件项目时,所消耗的工作量也不相同。一般常见的开发因素有:
采用技术:如开发该系统所用的语言、开发平台、系统架构、操作系统等。
开发团队:开发方的组织类型、团队规模、个人能力等。
过程能力:开发方的成熟度(如所具备的CMMI成熟度)、管理要求等。
工作量估算方法的选择:估算方法主要指:类比法、类推法、方程法。一般情况下估算工作量应由规模估算的结果作为输入,然后采取方程法进行估算。但是在一些特殊情况下,如因需求非常模糊,而无法进行规模估算时,可以直接采用类比和类推法直接估算工作量。
(2)估算与调整
【标准原文】
在进行工作量估算时,应:
a)根据风险分析结果,对估算方法或模型合理调整。如调整估算模型中影响因子的权重或取值,或根据风险分析结果进行软件完整性级别定义并根据完整性级别调整工作量估算结果;
b)根据可复用的规模及可复用程度对工作量估算进行调整;
c)采用不同的工作量估算方法时,分别遵循以下原则:
1)在使用类推法时,参考的历史项目应和待估算项目有高度的相似性。在估算时应识别出待估算项目与参考历史项目的主要差异并对估算结果进行适当调整;
2)在使用类比法时,应根据主要项目属性对基准数据进行筛选;当用于比对的项目数量过少时,宜按照不同项目属性分别筛选比对,综合考虑工作量估算结果;
3)在使用方程法时,宜基于基准数据,并采用回归分析方法,建立回归方程。可根据完整的多元方程(包含所有工作量影响因子),直接计算出估算结果;也可根据较简单的方程(包含部分工作量影响因子),计算出初步的工作量估算结果,再根据其他调整因子,对工作量估算结果进行调整。
宜采用不同的方法分别估算工作量并进行交叉验证。如果不同方法的估算结果产生较大差异,可采用专家评审方法确定估算结果,也可使用较简单的加权平均方法。
在估算工作量时,宜给出估算结果的范围而不是单一的值。例如,可采用基准比对方法,根据基准数据库中25百分位数、50百分位数和75百分位数的功能点耗时率数值,分别计算出工作量估算的合理范围与最有可能值。
示例:
假设基于基准数据建立的回归方程为:
UE=C×S0.9
式中:
UE——未调整工作量,单位为人时(ph);
C——生产率调整因子,单位为人时每功能点(ph/FP);
S——软件规模,单位为功能点(FP)。
假设根据相关性分析和经验确定调整后工作量计算公式为:
AE=UE×A×L×T
式中:
AE——调整后工作量,单位为人时(ph);
A——应用领域调整因子,取值范围0.8~1.2;
L——开发语言调整因子,取值范围0.8~1.2;
T——最大团队规模调整因子,取值范围0.8~1.2。
假设待估算项目的规模为1000FP,参考基准数据的功能点耗时率25百分位数、50百分位数和75百分位数,C取值分别为8ph/FP、10ph/FP、14ph/FP,则计算出未调整工作量合理范围介于4009.50ph与7016.62ph之间,未调整工作量最有可能值为5011.87ph。
假设根据参数表确定应用领域调整因子取值为1,开发语言调整因子取值为0.8,最大团队规模调整因子取值为1.1,则计算出调整后工作量合理范围介于3528.36ph与6174.63ph之间,调整后工作量最大可能值为4410.45ph。
因项目变化导致需要重新进行工作量估算时,应根据该变化的影响范围对工作量估算方法及估算结果进行合理调整。
【标准释义】
风险分析:在进行工作量估算时,应首先考虑风险分析的结果。通过风险分析的结果,对工作量估算模型中的因子设置不同的权重和取值。也可以通过风险分析,获得对于软件完整性级别的定义。
关于软件的完整性级别的描述和定义,可参考《GB/T 18492-2001信息技术系统及软件完整性级别》。
调整复用度:在对整个工作量估算模型进行调整之后,需要针对复用程度来对工作量进行调整。这种调整建议在规模估算之后进行。例如在用快速功能点方法(方法介绍详见附录C)估算出内部逻辑文件和外部接口文件之后,可以考虑针对每个逻辑文件分析其复用程度。然后对逻辑文件的功能点数进行调整。这种调整虽然表现为调整了功能点数,但其实质目的还是为了调整工作量。针对每一个逻辑文件进行调整,可以更好地反映出不同功能的复用对于整体工作量的影响。
类推法:属于以“估”为主的方法。将待评估项目与过去的一个或多个项目进行比较推算,确定特别相似和不同的地方,最后基于这种差异来进行实际工作量的调整。
采用类推法时应注意,所选择的历史项目与待评估项目一定要是高度相似的,历史数据尽量选择本组织内的数据,并且一定要对差异之处进行调整。虽然类推法是迄今为止理论上最可靠的估算方法,由于它是以“估”为主的,脱离不了评估人员的主观性,所以估算结果经常产生极大偏差。
示例如下:
项目描述:为政府部门甲新开发一款OA系统,以支持其网上办公、文档流转等电子政务需求。
历史项目情况:政府部门乙开发过类似系统,甲、乙部门对功能要求有所差别,但项目规模、难度、质量要求等差异不大。
参考项目数据如下:开发总工期为4.92个月,总工作量为4625人时,其中项目策划阶段78人时,需求阶段555人时,设计阶段694人时,构建阶段1619人时,测试阶段922人时,移交阶段757人时。
估算工作量:考虑到该项目可将之前为乙部门开发的系统作为原型了解客户需求,假设需求分析阶段可减少约1/3工作量,则预计项目工作量=(555×2/3+694+1619+922+757)人时=4440人时。
类比法:属于以“算”为主的方法。当待评估项目与已完成项目在某些项目属性(如应用领域、系统规模、复杂度、开发团队经验等)类似时,可使用类比法。它基于大量历史项目样本数据来确定目标项目的预测值。
采用类比法时应注意,当供选择的样本数量不足时,可以通过选择单个项目属性进行筛选比对,根据结果进行工作量的调整。
示例如下:
项目描述:为政府部门甲新开发一款OA系统,以支持其网上办公、文档流转等电子政务需求。
主要属性识别:可以识别出项目的3个主要属性是开发类型、业务领域和应用类型,分别为“新开发”,“政府”,“OA”。
筛选比对:假设查询行业基准数据库后发现,同时符合3个筛选条件的项目只有5个,数量过少,因此选择单一属性分别比对,获得如表2-6工作量数据(单位为人时)查询结果:
表2-6 不同属性工作量对比

估算工作量:则该项目所需工作量的最有可能值为(5892+4713+5128)/3,即5244人时。工作量估算的合理范围大致在2141人时和9623人时之间(采用P25和P75的值分别计算平均值)。
方程法:采用方程法进行工作量估算时,应考虑根据开发组织实际情况进行回归分析,建立回归方程。关于回归分析的方法,可参考其他章节中关于回归分析的介绍。可将所有影响因子都考虑在内建立多元方程,也可以先根据部分影响因子算出初步的结果,再对结果进行调整。
行业级模型示例如下:
行业级模型:
AE=(S×PDR)×SWF×RDF
公式中:
AE——调整后工作量,单位为人时;
S——规模,单位为功能点数;
PDR——生产率,单位为人时每功能点;
SWF——软件因素调整因子;
RDF——开发因素调整因子。
交叉验证:建议使用多人采取不同的估算方法来分别进行工作量估算,并对结果进行分析。不同的估算方法也包括同样适用方程法,但是使用不同的数学方程分别进行估算。当不同的估算者获得自己的估算结果之后,应对结果进行分析,如果差距在可以接受的范围内,则无须进一步分析原因,可直接以平均值作为估算结果。如果不同估算者的结果间差距过大,则需要进一步分析差距产生的原因,调查进行估算的假设条件是否存在问题。在对差距原因进行分析的基础上,可使用专家评审法确定结果,也可以使用简单的加权平均方法获得估算结果。
工作量估算的结果:工作量估算的结果受到各种因素影响,很难得到一个固定的值,进行工作量估算的主要目的,更多的是了解待开发系统在功能规模一定的情况下可能的工作量水平。所以工作量估算的结果一般以一个范围的形式呈现,表示出工作量的最可能值,以及合理的范围。可参考统计方法中的百分位法,以P50来表示最可能的值,P25,P75来表示合理范围值得下限和上限。采用类推类比法的时候,可以直接取得相应的值。如果使用方程法,则需要在基准数据中选择功能点耗时率的P50(代表有50%的数据不大于该值),P25(代表只有25%的数据不大于这个值),P75(代表有75%的数据不大于这个值)三个值,然后以功能点数分别乘以这三个值,即得到工作量的范围:
功能点数×功能点耗时率P25=下限
功能点数×功能点耗时率P50=最可能值
功能点数×功能点耗时率P75=上限
工作量估算的结果是建立项目目标及承诺的基础。在实际的项目过程中,应根据项目特点及约束选择合适的估算结果。例如,在制定项目预算时,如果为了保证项目有充足的预算以按时按质交付,则可依据估算结果的上限编制预算;而在编制项目计划时,可以依据估算结果的最有可能值。
4.估算工期
【标准原文】
在估算工期时,应:
a)根据工作量估算结果和资源情况,对工作任务进行分解并制订工作时间表。在制定工作时间表时,应充分考虑关键路径任务约束对工期的影响。如用户参与需求沟通活动的资源投入情况、委托方对试运行周期的要求等;
b)利用基准数据估算合理的工期范围。可利用基准数据,建立“工作量-工期”模型,使用方程法估算合理的工期范围;也可使用类比法,估算合理的工期范围;
c)将委托方的期望工期或开发方初步制订的工作时间表中的工期与工期估算结果进行比较;
d)如果委托方期望工期或工作时间表中的工期短于估算出的工期下限时,应分析原因,必要时需对人力资源安排或项目范围进行调整,再重新估算工作量、工期,并制订新的工作时间表。
【标准释义】
项目工期估算是根据估算结果、项目范围、资源状况列出项目活动所需要的工期,估算的工期应该现实、有效并能保证质量。所以在估算工期时要充分考虑活动清单、合理的资源需求、人员能力、客户及环境因素对项目工期的影响,在对每项活动的工期估算中也应充分考虑风险因素对工期的影响。项目工期估算完成后,可以得到量化的工期估算数据。在估算工期时应包含如下步骤:
a)根据工作量估算结果和资源情况,对工作任务进行分解并制订工作时间表。在制定工作时间表时,应充分考虑如下因素:
——关键路径任务约束对工期的影响。如用户参与需求沟通活动的资源投入情况、委托方对试运行周期的要求等;
——识别干系人,并理解他们对项目的影响力也是至关重要的,不同的项目干系人可能对哪个因素最重要有不同的看法,从而使问题更加复杂,如果这项工作没有做好,将可能导致项目工期延长或成本显著提高。例如,没有及时将法律部门作为重要的干系人,就会导致因重新考虑法律要求而造成工期延误或费用增加。
b)利用基准数据估算合理的工期范围。可利用基准数据,建立“工作量-工期”模型,使用方程法估算合理的工期范围;也可使用类比法,估算合理的工期范围。
在掌握大量数据的基础上,可利用回归分析法,通过数理统计方法建立因变量(工期)与自变量(工作量)之间的回归关系函数表达式,即回归方程。建立了“工作量-工期”模型后,可利用此模型对项目工期进行预测,预测结果建议作为参考,不要直接用于制定项目计划,需按步骤a)描述考虑项目具体因素进行调整。
回归分析法有多种类型。依据相关关系中自变量的个数不同分类,可分为一元回归分析预测法和多元回归分析预测法。在一元回归分析预测法中,自变量只有一个,在多元回归分析预测法中,自变量有两个以上。依据自变量和因变量之间的相关关系不同,可分为线性回归预测和非线性回归预测。通过行业数据统计的“工作量-工期”关系如图2-1所示,图中表达了一元非线性回归方程:
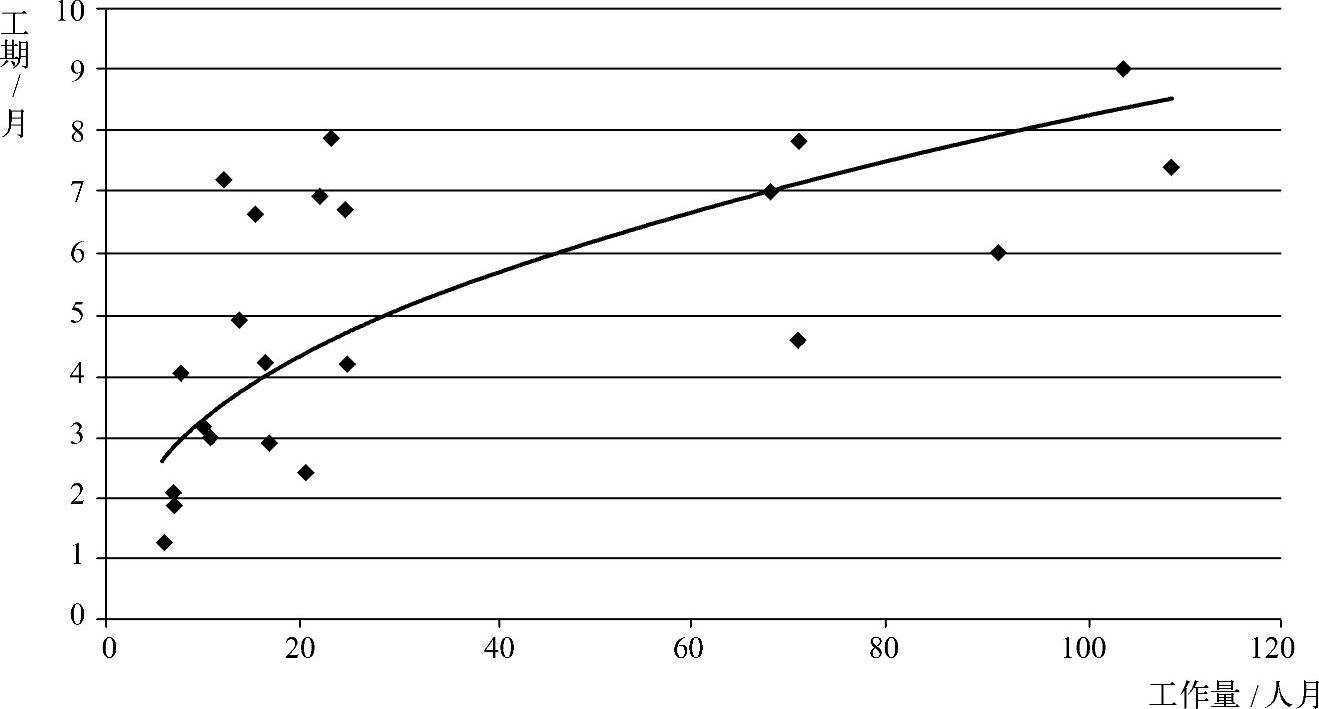
图2-1 工作量与工期关系
回归分析预测法的步骤如下:
a)根据预测目标,确定自变量和因变量。明确预测的具体目标,也就确定了因变量。如预测具体目标是工期,那么工期Y就是因变量。寻找与预测目标的相关影响因素,即自变量,并从中选出主要的影响因素。“工作量-工期”模型只选择工作量为自变量。
b)建立回归预测模型。依据自变量和因变量的历史统计资料进行计算,在此基础上建立回归分析方程,即回归分析预测模型。
c)进行相关分析。回归分析是对具有因果关系的影响因素(自变量)和预测对象(因变量)所进行的数理统计分析处理。只有当自变量与因变量确实存在某种关系时,建立的回归方程才有意义。因此,作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。进行相关分析,一般要求出相关系数,以相关系数的大小来判断自变量和因变量的相关的程度。
d)检验回归预测模型,计算预测误差。回归预测模型是否可用于实际预测,取决于对回归预测模型的检验和对预测误差的计算。回归方程只有通过各种检验,且预测误差较小,才能将回归方程作为预测模型进行预测。
e)计算并确定预测值。利用回归预测模型计算预测值,并对预测值进行综合分析,确定最后的预测值。
正确应用回归分析预测时应注意:
——用定性分析判断现象之间的依存关系;
应用回归预测法时,应首先确定变量之间是否存在相关关系。如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果。
——避免回归预测的任意外推;
——应用合适的数据资料。
项目管理应用中在制定进度和风险管理时也经常用到蒙特卡罗方法,蒙特卡罗方法是以概率和统计的理论和方法为基础的一种数值计算方法。它将所求解的问题同一个概率模型相联系,用计算机实现统计模拟或抽样,从而求得问题的近似解。该分析方法也称为统计试验法或统计模拟法。这是一种模拟技术,模拟指以不同的活动假设为前提,计算多种项目所需时间,该种分析对每项活动都定义一个结果概率分布,以此为基础计算整个项目的结果概率分布,此外,还可以用逻辑网络进行“如果……怎么办”分析,以模拟各种不同的情况组合,例如推迟某重要配件的交付、延迟具体工程所需时间或者把外部因素(例如罢工、或政府批准过程发生变化)考虑进来。“如果……怎么办”分析的结果可用于评估进度在恶劣条件下的可行性,并可用于制定应急/应对计划,克服或减轻意外情况所造成的影响。
f)将委托方的期望工期或开发方初步制定的工作时间表中的工期与工期估算结果进行比较。通过行业数据统计的工期数据,以及不同工期下的实际成本如图2-2所示:
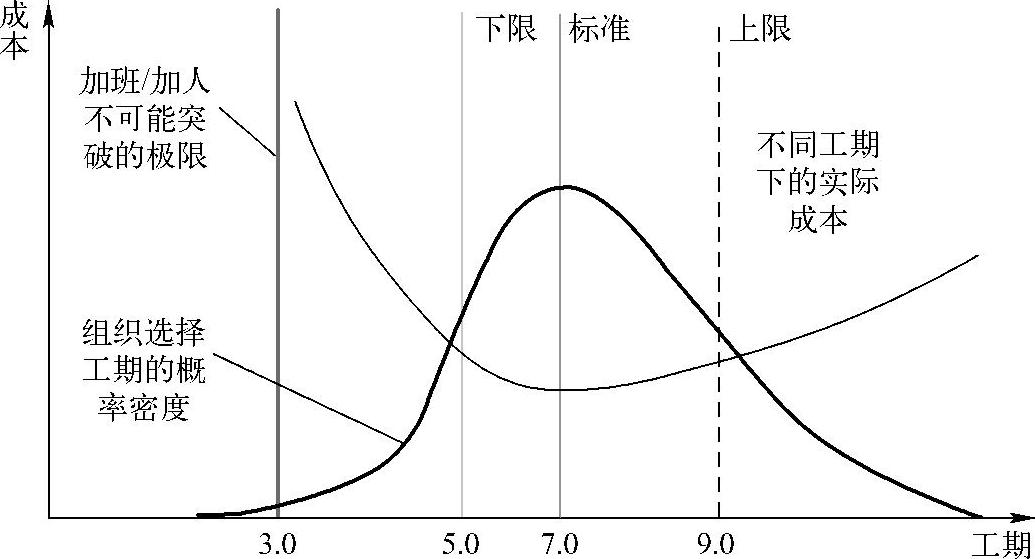
图2-2 不同工期下实际成本
图2-2中下限、标准、上限值分别对应行业工期数据统计的P25、P50、P75,代表此工期下成功交付项目的比例数,也代表项目成功的概率。
——如委托方的期望工期或开发方初步制定的工作时间表中的工期长于模型标准值时,开发方只需要考虑资源投入。
——如委托方的期望工期或开发方初步制定的工作时间表中的工期短于或等于模型标准值时,则需要压缩工期并考虑相关的项目风险。
进度压缩是指在不改变项目范围的前提下,缩短项目的进度时间,以满足进度制约因素、强制日期或其他进度目标。进度压缩技术包括:
——赶工。通过权衡成本与进度,确定如何以最小的成本来最大限度地压缩进度。赶工的例子包括:批准加班、增加额外资源或支付额外费用,从而加快关键路径上的活动。赶工并非总是切实可行的,它只适用于那些通过增加资源就能缩短持续时间的活动,它也可能导致风险或成本的增加,如增加的额外资源不能及时到位等。
——快速跟进。把正常情况下按顺序执行的活动或阶段并行执行。例如,需求分析尚未全部完成前就开始进行设计或编码。快速跟进可能造成返工和风险增加,且关键路径上并行任务数增多,任一个任务延迟都将导致项目延期。
g)如果委托方期望工期或工作时间表中的工期短于估算出的工期下限时,应分析原因,必要时需对人力资源安排或项目范围进行调整,再重新估算工作量、工期,并制定新的工作时间表。
从图2-2可以看出,随着资源的增加,工期并不能随之相应减少,工期存在通过加班/加人不可能突破的极限。
项目有具体的制约因素,任何一个因素发生变化,都会影响至少一个其他因素。例如,缩短工期通常都需要提高预算,以增加额外的资源,从而在较短时间内完成同样的工作量;如果无法提高预算,则只能缩小范围或降低质量,以便在较短时间内以同样的预算交付产品,项目经理需关注项目具体的制约因素及这些因素间的关系,合理安排项目工期,否则就可能影响项目成功交付。
5.估算成本
(1)估算直接人力成本
【标准原文】
应根据工作量估算结果和项目人员直接人力成本费率估算直接人力成本。直接人力成本费率是指每人月的直接人力成本金额,单位通常为元每人月或万元每人月。直接人力成本的计算宜采用以下两种方式之一:
a)根据不同类别人员的直接人力成本费率和估算工作量分别计算每类人员的直接人力成本,将各类人员的直接人力成本相加得到该项目的直接人力成本;
b)根据项目平均直接人力成本费率和估算的总工作量直接计算该项目的直接人力成本。直接人力成本的计算公式为:

式中:
DHC——直接人力成本,单位为元;
n——人员类别数量,取值为不小于1的自然数;
Ei——第i类人员的工作量,单位为人月;
IFi——第i类人员的直接人力成本费率,单位为元每人月。
在估算项目直接人力成本费率时,应考虑不同地域人员成本的差异。委托方可参照同类项目的直接人力成本费率数据;开发方应优先使用本组织的直接人力成本费率数据。
【标准释义】
通常在早期估算时,可根据平均人力成本费率确定人力成本,平均人力成本费率受物价指数、行业、人力资源供给状况、企业所在地、工作性质、人员级别等因素影响。如可根据不同角色进行估算,一般情况下总体架构师的人力成本费率高于需求分析师,需求分析师的人力成本费率高于编程工程师,而同种角色会有多个人员级别设置,级别越高,平均人力成本费率越高。
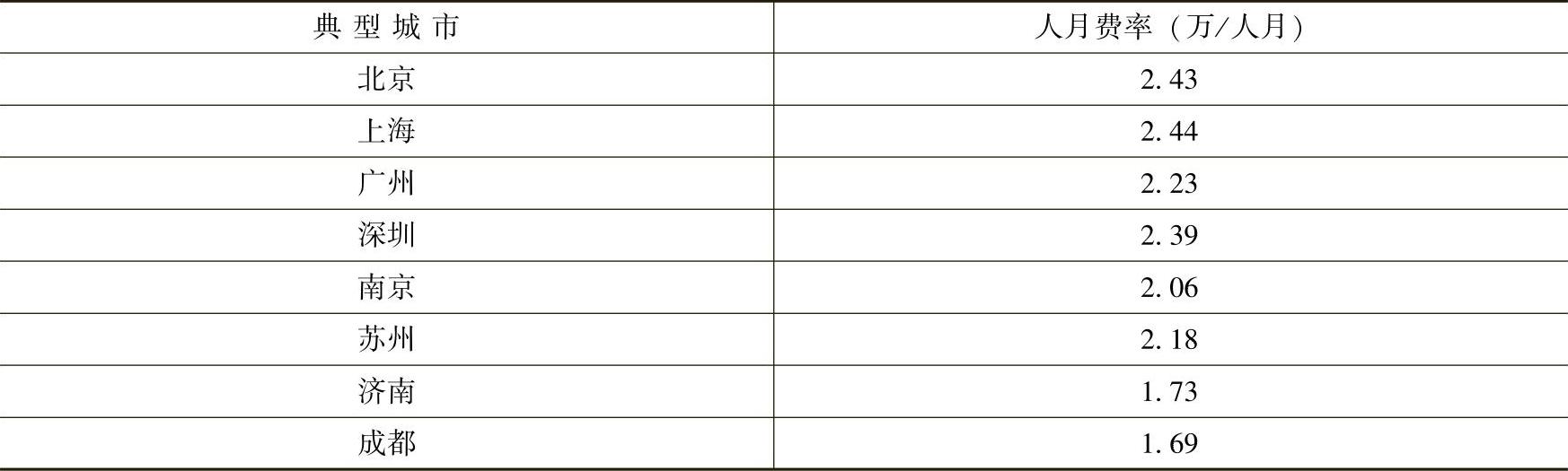
据北京软件造价评估技术创新联盟发布的2016年行业基准数据(CSBMK-201610),北京2016年平均人力成本费率为2.43万/人月,该人月费率代表该北京地区行业中位数(P50),费用包含软件的直接人力成本、间接成本及合理利润,但不包括直接非人力成本。不同地域、不同城市间的平均人力成本费率也有较大差异。表2-7为2016年各典型城市人月费率。
表2-7 2016年典型城市人月费率基准数据明细
(2)估算直接非人力成本
【标准原文】
宜根据项目情况,按照本标准第4章的要求分项估算直接非人力成本,也可依据基准数据或经验估算。
示例1:项目成员因项目加班而产生的餐费宜计入直接非人力成本中的办公费,而项目成员的工作午餐费宜计入直接人力成本。
示例2:项目组封闭开发租用会议室而产生的费用宜计入直接非人力成本中的办公费,而研发部例会租用会议室产生的费用宜按照间接非人力成本分摊。
示例3:为项目采购专用测试软件的成本宜计入直接非人力成本中的采购费,而日常办公用软件的成本宜按照间接非人力成本进行分摊。
【标准释义】
直接非人力成本通常与工作量没有关系,有些项目直接非人力成本可忽略不计,需根据项目实际情况进行估算,如项目在异地开发,则差旅费会较多。
(3)估算间接人力成本
【标准原文】
宜根据项目情况,按照本标准第4章的要求分项估算间接人力成本。间接人力成本宜按照工作量比例进行分摊。
示例:质量保证部门的质量保证人员甲负责组织级质量保证工作和3个项目(A、B、C)的项目级质量保证工作。其中,用于项目A、B、C的工作量各占总工作量的1/4,用于组织级质量保证工作和其他工作的工作量占其总工作量的1/4;同时,项目A的研发总工作量占该组织所有研发项目总工作量的1/3,则质量保证人员甲的人力资源费用中,1/4计入项目A的直接人力成本,1/12(占质量保证工程师甲1/4的组织级质量保证工作和其他工作中,只有1/3计入项目A的成本)计入项目A的间接人力成本。
【标准释义】
间接人力成本一般按人工投入比例进行分摊,也可根据公司情况确定不同的分摊方式,如按部门粗略分摊等。
(4)估算间接非人力成本
【标准原文】
宜根据项目情况,按照本标准第4章的要求分项估算间接非人力成本。间接非人力成本宜按照工作量比例进行分摊。
示例:公司甲有员工200人,1年的房屋租赁费为人民币120万元,则每人每月的房租分摊为500元,如果项目A的总工作量为100人月,则分摊到项目A的房屋租赁费为人民币5万元(即100人月×500元/人月)。
【标准释义】
间接非人力成本一般按人工投入工作量进行分摊,也可根据公司情况确定不同的分摊方式,如按部门粗略分摊等。
(5)确定软件研发成本
【标准原文】
软件研发成本的计算公式通常为:
SDC=DHC+DNC+IHC+INC (2)
式中:
SDC——软件研发成本,单位为元;
DHC——直接人力成本,单位为元;
DNC——直接非人力成本,单位为元;
IHC——间接人力成本,单位为元;
INC——间接非人力成本,单位为元。
在估算软件研发成本时,可根据直接人力成本费率估算人力成本费率(即每人月直接人力成本与分摊到每人月的间接成本之和),计算公式为:
F=IF×(1+DP) (3)
式中:
F——人力成本费率,单位为元每人月;
IF——直接人力成本费率,单位为元每人月;
DP——间接成本系数,即分摊到每人月的间接成本占每人月直接人力成本的比例。
委托方和第三方宜参照行业基准数据确定DP的取值。
如果已经获得了人力成本费率,则可以依据工作量估算结果和人力成本费率直接计算出直接人力成本和间接成本的总和,然后再计算软件研发成本,计算公式为:
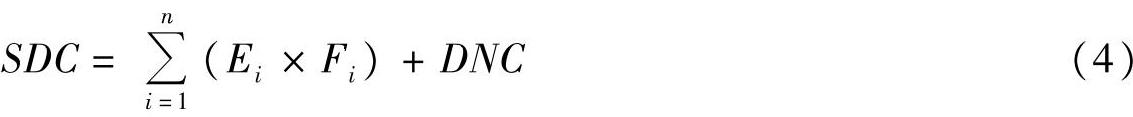
式中:
SDC——软件研发成本,单位为元;
n——人员类别数量,取值为不小于1的自然数;
Ei——第i类人员的工作量,单位为人月;
Fi——第i类人员的人力成本费率,单位为元每人月;
DNC——直接非人力成本,单位为元。
委托方可根据行业基准数据确定每人月直接人力成本与分摊到每人月的间接成本的比例,进而估算人力成本费率。
对于委托方,如果已经确定了规模综合单价,则可以根据规模综合单价和估算出的规模直接计算出直接人力成本和间接成本的总和,然后计算软件研发成本,计算公式为:
SDC=P×S+DNC (5)
式中:
SDC——软件研发成本,单位为元;
P——规模综合单价,单位为元每功能点;
S——软件规模,单位为功能点;
DNC——直接非人力成本,单位为元。
【标准释义】
通常采用三种方法确定软件研发成本:
a)分别计算直接人力成本、直接非人力成本、间接人力成本、间接非人力成本,然后求和计算软件研发成本;
b)依据工作量估算结果和平均人力成本费率直接计算出直接人力成本和间接成本的总和,加直接非人力成本计算软件研发成本;
对于委托方,也可利用不含毛利润的开发方人力成本费率(只包含直接人力成本和间接成本)估算软件研发成本,再根据开发方毛利润水平,确定预算费用;
c)依据规模估算结果和规模综合单价直接计算出直接人力成本和间接成本的总和,再加直接非人力成本计算软件研发成本。
实际应用中多采用第二种或第三种方法确定软件研发成本。如果委托方和开发方对规模估算方法一致认可,且均能熟练掌握,可采用第三种方法,此种方法更能适应项目范围存在较大变更概率的项目,可支撑委托方的费用预算审批,也可保护开发方的利益,此时,规模估算结果必须作为附件提交,如采用功能点方法进行规模估算的项目,上报预算时还应附上功能清单及对应功能点数。
上报预算时应依据规模、工作量、工期、成本、预算金额的估算结果,并考虑此类项目的特殊因素。例如,对于质量、进度要求较高的项目,为了确保项目成功可按照预算金额的上限值上报预算。如无特殊情况,不应以低于预算金额下限或高于预算金额上限的金额上报预算。
有关软件研发成本度量规范释义的文章

《软件研发成本度量规范》标准适用于度量成本与功能规模密切相关的软件研发项目的成本。《规范》中的规模估算可依据其中任一方法识别功能点计数项,并根据其对应的权值计算出软件功能规模。总之,《规范》在软件行业的应用,将带来软件行业甲乙双方双赢的结果,可以维护市场健康有序发展。《规范》的应用,将为乙方在甲乙双方谈判中提供有利的谈判筹码。......
2023-11-19

在项目开展期间,甲乙双方采用WBS分解结合经验法、类比法等方法对估算结果进行进一步的验证。以下简单描述采用类比法对成本估算结果的验证情况。类比法即将本项目的部分属性与类似的一组基准数据进行比对,进而获得待估算项目工作量、工期或成本估算值的方法。双方约定,任丽萍作为需求方唯一接口人,所有需求必须经由任丽萍才能提出,所有需求变更均须经过项目领导小组认可。......
2023-11-19
相反,在整个软件研发项目的生命周期中,还需要持续不断地对软件研发成本进行测量和分析。而直接人力成本最直接的测量因素就是工作量,因此在软件研发过程中,可以只跟踪直接非人力成本和工作量。项目结束后测量成本:在软件项目结束后,为了解软件开发项目的整体成本状况,则有必要根据本标准第4章的要求,对各项成本分别进行测量。......
2023-11-19

A.2.3 投标A.2.3.1 投标准备投标方接到招标文件后,应对招标文件中与投标报价相关的内容进行澄清和确认,明确项目的范围和边界,并结合自身经验和项目实际情况整理出功能清单及对应功能点数。A.2.3.2 估算应由具备本标准涉及的成本估算能力的人员按照5.1的规定进行估算。A.2.3.3 确定投标报价投标方不得以低于成本的报价竞标。A.2.3.4 形成投标文件投标方应根据A.2.3.2的估算结果和A.2.3.3确定的投标报价,形成投标文件中相应部分的内容。......
2023-11-19

根据国际、国内调研情况,确定了标准的关键技术路线和编制思路。起草组根据评审意见讨论修改后,形成正式的征求意见稿。定向发送征求意见稿给123家机构,并从2012年6月1日至6月30日在全国信标委网站上征求意见。2013年10月23日,工业和信息化部批准《软件研发成本度量规范》正式发布,并于12月1日正式实施。2013年11月8日,工业和信息化部行业标准《软件研发成本度量规范》发布会在北京市中关村软件园隆重召开。......
2023-11-19

由于制定《软件研发成本度量规范》的主要目的之一是指导相关组织或个人科学、统一地开展软件研发成本估算活动,这是因为在进行软件研发成本估算时,规模估算通常是重要的基础。对于此类项目,在估算了功能规模后,可以通过引入合理的调整因子进行有效的成本估算,也可以对项目中的特殊任务单独估算或调整。......
2023-11-19

快速功能点度量方法是由北京软件造价评估技术创新联盟依据国际ISO标准要求提出的一种软件规模度量方法,并充分考虑组织及需求或项目特性,目前采用预估功能点和估算功能点进行业务需求规模的估算和测量,并对方法进行了优化改进。......
2023-11-19

效果评价1、公司提出的预算得到甲方的验证与认可通过应用行业标准、行业基准数据,该项目进行了第三方的评估,该公司以评估结果帮助甲方进行了预算申报。......
2023-11-19
相关推荐