在显示个人化广告时,不会将Cookie或匿名标识符与敏感类别建立联系。但这通常需要获得用户同意,否则不会将Cookie数据与身份识别数据合并使用。数据应在保留期结束时以安全的方式被销毁。除法律另有规定外,企业如将个人数据向第三方公开,至少应当确保接收这些数据的企业承担遵守法案原则的合同义务。......
2023-11-18
基于数据失真的技术通过添加噪声和交换等技术对原始数据进行扰动处理,使敏感数据失真但同时保持某些数据或数据属性不变,仍然可以保持某些统计方面的性质。常用方法如下[17]:
(1)数据变换法[18] 通过降低原数据中私有信息的支持度或置信度至某个阈值来实现隐私数据保护。在实际操作中往往是通过删除或增加数据项来达到此目的。
(2)凝聚技术[19] 将原始数据分类,每类中包含k个数据,然后生成每类数据的统计信息,包括均值和方差等。这样所有扰动后的数据可以使用通用的重构算法进行处理,同时不会泄露原始数据的隐私。
(3)差分隐私[20] 差分隐私是微软研究院在2006年提出的一种新隐私保护模型。其主要贡献是:①定义了一个相当严格的攻击模型,不关心攻击者拥有多少背景知识,即使攻击者已掌握除某一条记录之外的所有记录信息,该记录的隐私也无法被披露;②对隐私保护水平给出了严谨的定义和量化评估方法。由于差分隐私的诸多优势,使其一出现便迅速取代传统隐私保护模型,并引起了理论计算机科学、数据库、数据挖掘和机器学习等多个领域的关注。
(4)数据干扰法[21] 通过加入噪声数据,使数据无法辨认以保护真实的原始数据。利用数据干扰法后,原始数据中将存在一定的干扰数据,所以即便某数据项被链接到某特指的个体也不会完全暴露数据的真实值,因此不会泄露私有信息。(www.chuimin.cn)
数据干扰法是目前采用最多的方法。使用此方法进行隐私数据保护的基本步骤是:首先数据发送方需要先在原始数据中进行关联规则挖掘;然后由专家对挖掘结果进行鉴定,将结果集区分为隐秘性及非隐秘性数据;接着利用干扰技术对原始数据内容进行转换,即修改与隐秘性数据样本相关的原始数据内容,借此将隐秘性数据加以隐藏而达到保护效果;最后再将转换后的数据对外公开。数据接收方对转换后的数据进行关联规则挖掘,仅能挖掘出非隐秘性数据集。其过程如图5-2所示。
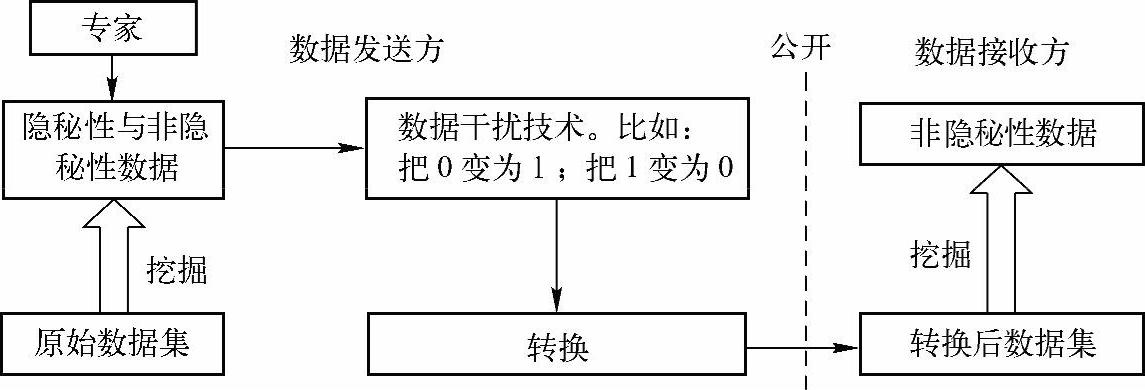
图5-2 数据干扰法操作示意
有关云安全深度剖析:技术原理及应用实践的文章

在显示个人化广告时,不会将Cookie或匿名标识符与敏感类别建立联系。但这通常需要获得用户同意,否则不会将Cookie数据与身份识别数据合并使用。数据应在保留期结束时以安全的方式被销毁。除法律另有规定外,企业如将个人数据向第三方公开,至少应当确保接收这些数据的企业承担遵守法案原则的合同义务。......
2023-11-18

目前,对于隐私保护的研究主要包含两个方面。有关云计算的隐私安全保护技术已经成为学术界和产业界关注的热点话题之一。参考文献[9]总结了云计算数据安全、法律法规和不同国家标准等相关的隐私争议。参考文献[10]调查了多种因素影响云计算隐私和安全问题。比如,ISO/IEC提出了一种隐私保护框架,该框架的主要内容包括了隐私保护过程中涉及的角色、数据信息、术语、隐私泄露风险、隐私保护需求和隐私保护原则等。......
2023-11-18

IaaS层数据的机密性、完整性和可用性三个方面是用户对于存储数据关注的核心安全问题,也是云存储安全技术的研究重点。比如SalesForce采用SSL 3.0和TLS 1.0保证数据的传输安全,SSL和TLS在传输层对数据进行加密,防止数据被截取和窃听。全同态加密机制可使用户的数据在其整个生命周期都处于加密状态,减少了数据泄露的概率。......
2023-11-18

限制发布是指有选择的发布数据或者发布精度较低的数据以实现对数据隐私的保护。有选择地发布敏感数据及可能披露敏感数据的信息,但保证对敏感数据及隐私的披露风险在可容忍范围内。基于限制发布的隐私保护技术主要包括K-Anonymity、L-Diversity和T-Closeness。因此在这K组数据中,用户的隐私得到有效的保护,其身份被泄露的概率将不大于1/K。......
2023-11-18

(一)大数据隐私保护技术1.匿名处理匿名是最早提出的隐私保护技术,将发布数据表中涉及个体的标识属性删除之后发布。减少发布数据的数量,使大部分隐私数据不会发生泄露,同时随着样本容量的减少,对原始数据的分析工作量增加。(二)大数据隐私保护机制隐私保护机制的模式一般分为交互模式和非交互式模式。非交互式场景主要研究的是如何设计高效的隐私保护发布算法使发布的数据既能够保证数据的实用性还能保护数据拥有者的隐私。......
2023-10-18

对比上述三项隐私保护技术可知:基于数据加密的隐私保护技术虽然能够保证数据良好精确性和安全性,但却会消耗较多的资源,导致实用性偏差;基于数据失真的隐私保护具有较高的应用效率,但却会导致部分的数据信息丢失;而这也正是基于限制发布的隐私保护技术的缺陷所在。......
2023-11-18

然而,危险并不局限于个人隐私泄露,还可能利用大数据对我们的行为进行挖掘、分析与预测。因此,随着大数据时代的来临,对隐私的定义也发生了改变。大数据时代的隐私主要是指公民个人的秘密,包括个人的行为、习惯和心理状态等。由此可见,这种需要明白告知并参与决定的个人数据支配权,是大数据时代保护个人隐私的重要机制之一。......
2023-11-18
因而要实现用户隐私的有效保护,需要各方共同采取强有力措施来积极应对。例如,扩大隐私保护范畴,将数据采集、数据分析等大数据的处理和利用过程纳入法律法规范畴,形成保护个人隐私的长效机制。[7]第二,完善对数据库海量信息综合运作的监管体系,明确触犯隐私红线的惩处方式。......
2023-10-20
相关推荐