人是运动训练管理中最积极和潜力最大的因素。只有对运动训练中的人进行科学有效的管理,协调好各方关系,充分调动其积极性,才能更好地提高运动训练管理的效果。按照不同层次教练员与运动员之间的限额比例确定各项目教练员人数。运动训练计划实施中的指导,主要是训练职能部门或管理者督促下属管理者、教练员完成计划规定任务的训练管理活动或方式,以及运动训练过程的方法、手段的指导和帮助。......
2023-11-17
自组织特征映射神经网络(Self-organizing Feature Map,SOFM)是由芬兰学者Kohonen在1982年提出的一种聚类学习方法。Kohonen在文章中把SOFM描述为 “一个高维数据的可视化和分析工具”[5]。SOFM目前主要用于不同领域的高维数据的聚类、分类、抽样和可视化。[6]SOFM属于竞争型自组织神经网络,是一种无监督的学习方法。[7]与其他神经网络不同,它只有两层,分别是输入层和输出层(或被称为竞争层)。输入层的各神经元和输出层的各神经元之间是相连的,而传统的SOFM输出层是二维的。图2-1分别显示了传统输出层为一维线性分布和二维矩形排列分布的情况,其主要特点如下。
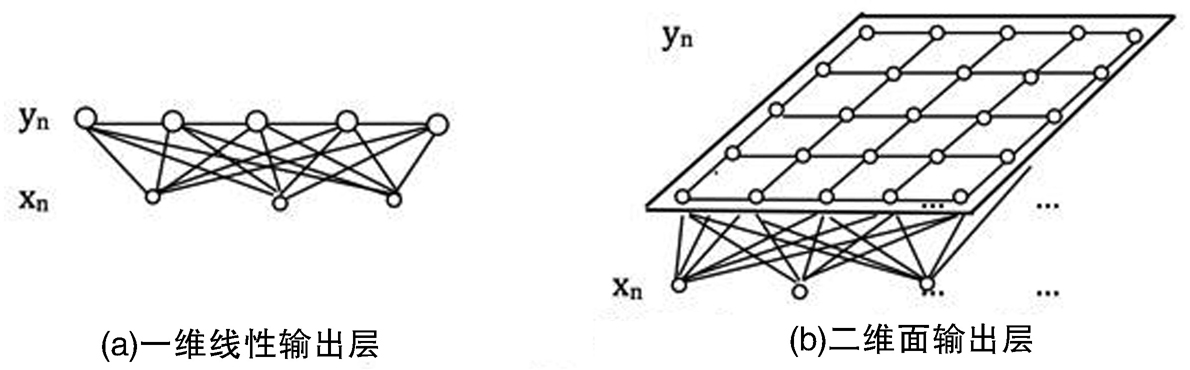
图2-1 SOFM 神经网络模型
(1)输入层的N维矢量数据将会映射到较低维度,对输入数据起到聚类、降维的作用。
(2)SOFM没有隐藏的输出神经元,输入数据的离散分布也会以同样规则的排列方式被映射到输出空间,也就是说,输出的神经元之间保留了原始数据之间的逻辑拓扑关系。
(3)不对输出分类的正确性或者“监督”进行评价,也就是说“没有指定明确的输出目标”[8]。
(4)具有自组织概率性质,能根据样本出现在输入空间的概率密度,自组织地形成与输入空间概率分布相对应的神经元的空间密度关系。
然而,传统的平面SOFM具有“边界效应”这一缺点。[9]在训练期间,神经元与其他单元竞争,获胜神经元及其“邻居”的权重将被更新,从而会对相似的数据区域进行建模。理想情况下,所有神经元都有平等的机会参与竞争,从而获得更新权重的机会。然而,在平面的输出层中,输出层边界处的单元拥有的邻居比平面内部单元少,在训练期间获得更新权重的机会无法和其内部的单元相同。因此,在训练结束时,边界处可能不会形成输入数据空间所期望的相似区域,从而导致“边界效应”。针对这种情况,研究者提出了优化的SOFM,如Kohonen从数据的角度,采用启发式加权规则法和局部线性平滑法对SOFM进行优化;还有学者提出将平面空间的边缘连接起来,形成无边缘的图形,例如球面或环面的SOFM,他们[10]将球面和平面的计算复杂度进行比较,结果发现球体形状不仅与传统的SOFM模型运行得一样快,而且在更短的训练周期内更准确地表达了数据。基于球面的SOFM,目前存在如下拓扑结构:GeoSOFM、S-SOFM(Spherical Self-organizing Feature Map)和H-SOFM。GeoSOFM由Wu等人[11]提出,如图2-2所示。他们采用二维矩形网格数据结构来存储二十面体的顶点数据,减少了维持栅格结构的计算开销,提高了顶点索引的速度,避免了在检索方面的性能损失。这种数据结构比较适合高维、可变的输出节点。
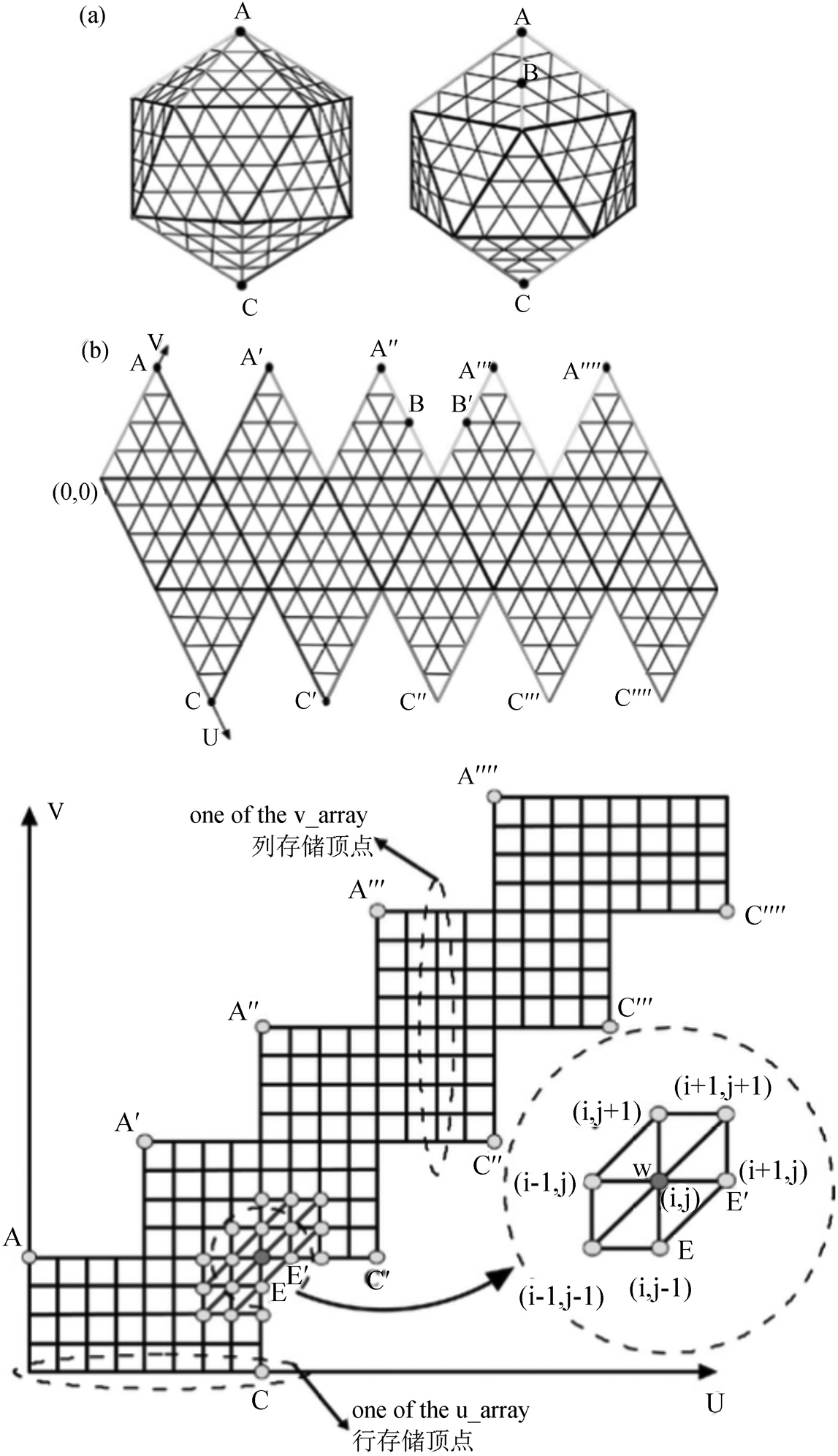
图2-2 GeoSOFM的数据存储结构
图2-3 显示了Sangole等人[12]构建的S-SOFM。每个网格单元会存储一个由其直接“邻居”生成的列表,并尝试在三维沉浸式虚拟现实环境中与S-SOFM进行交互式数据分析。
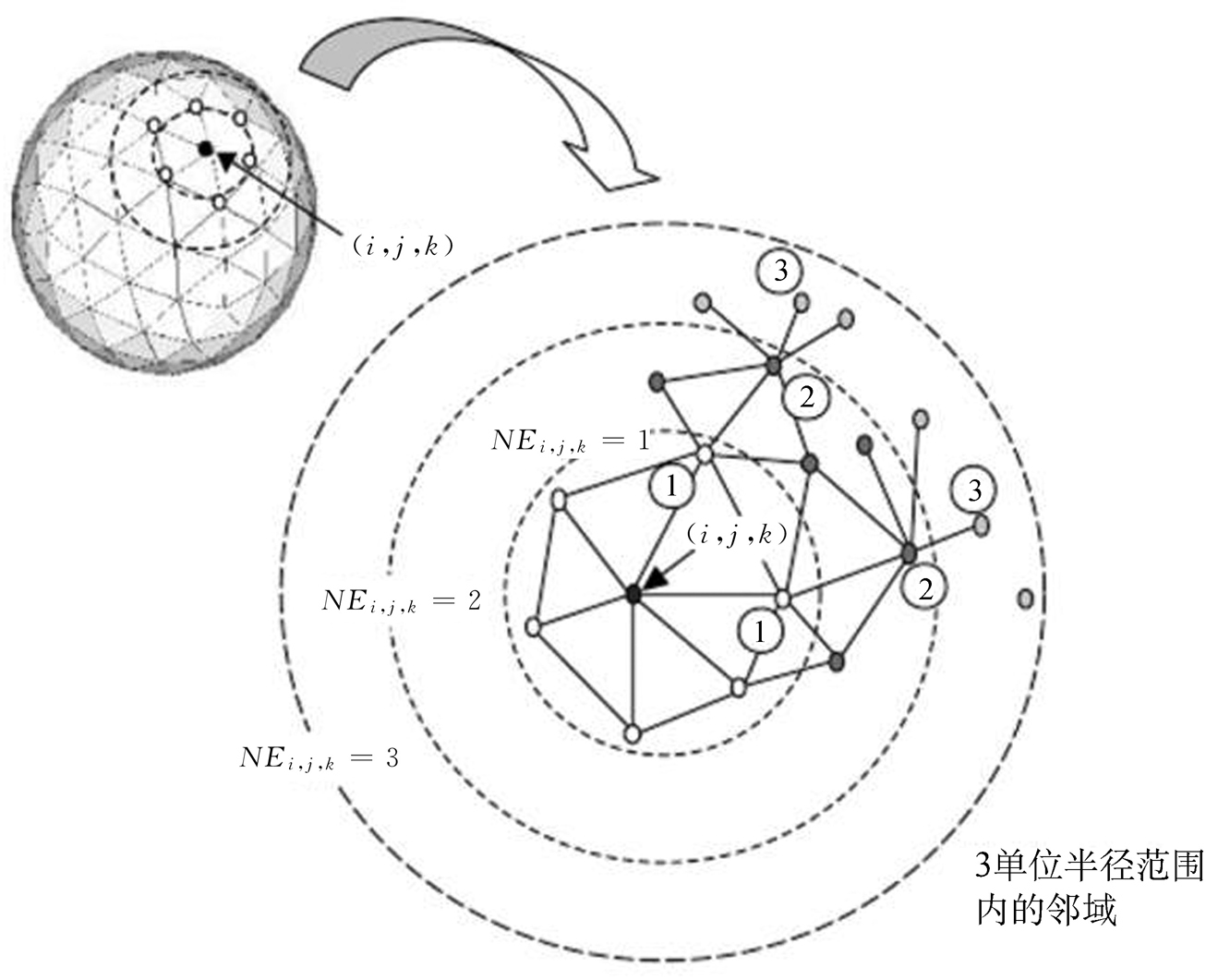
图2-3 S-SOFM结构
Boudjemai等人[13]构建了3D-SOFM模型,其主要目的是通过构建3D模型实现数据的可视化。Hirokazu等人[14]开发了H-SOFM沿螺旋排列神经元,把覆盖于球体表面的螺旋线分成相等的部分,并允许设定任意数量的神经元,不过在训练过程中,邻居节点的计算较复杂。在本书中,我们的工作主要是基于Sangole的S-SOFM工作成果,使邻居节点的管理方式和计算复杂度都能满足舞蹈姿态之间的强关联性。
 (www.chuimin.cn)
(www.chuimin.cn)
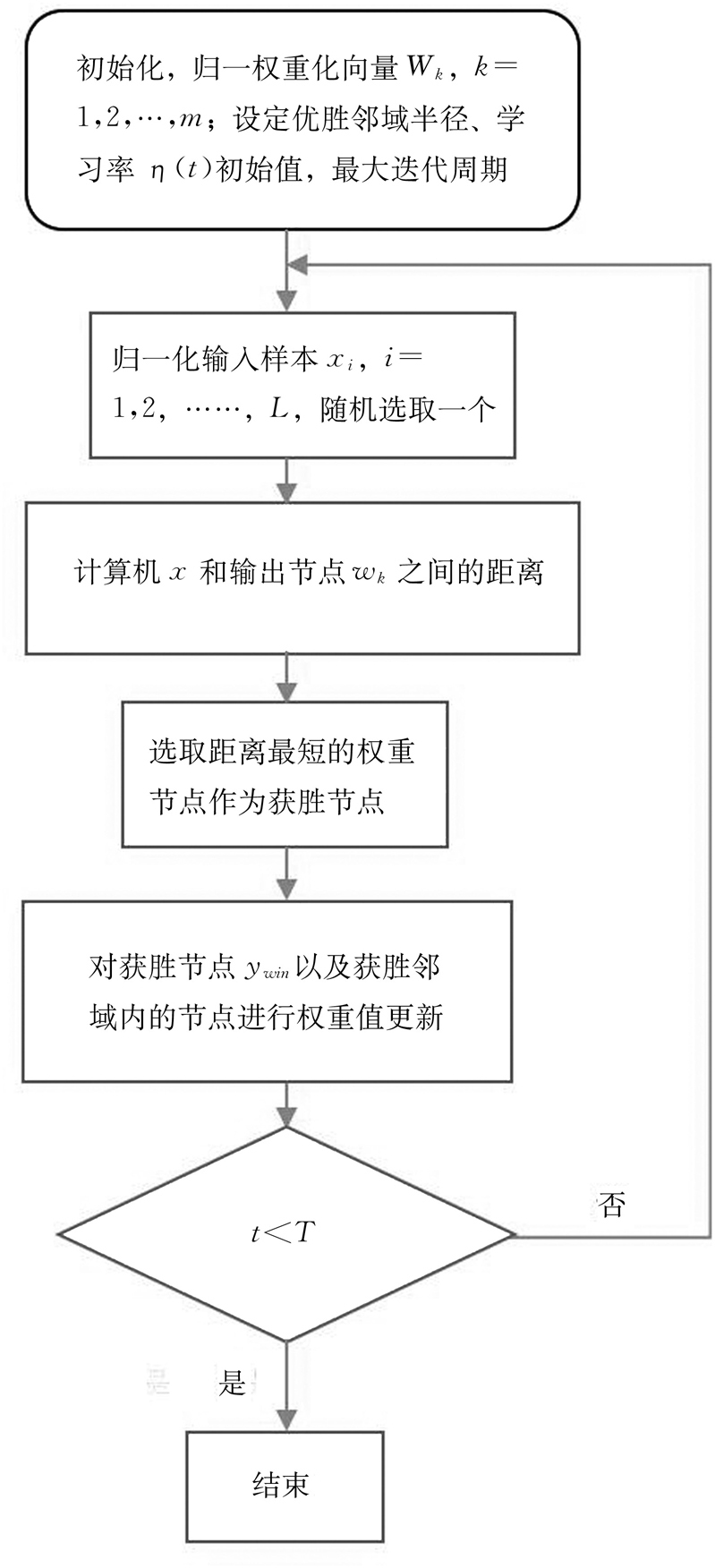
图2-4 S-SOFM算法过程
与2D的SOFM相比,S-SOFM继承了SOFM的优点:保持输入样本空间的拓扑结构不变,同时消除了“边界效应”;所有的神经元都有相等的几何区域,输入层特征空间中的密度区域在映射到S-SOFM之后具有相等间隔和以最大限度分离的对应节点位置;通过SOFM算法,对输入的样本在训练学习之后自动形成一种内部表达,最终将其映射到输出层中。如果以舞蹈动作为研究对象,那么输出层特征空间的建立实际上就是将已有的舞蹈动作作为训练样本,输入到S-SOFM空间中进行聚类的过程。最终可以在输出的球面空间中形成更易于识别的人体运动轨迹,通过识别这些轨迹,能有效地区分相对复杂的人体动作。此外,由于从球体中读取复杂的高维度信息更加直接、容易,因此S-SOFM具有更好的可视化效果,聚类后的结果可以通过直观的方式观察到。图2-4的流程图显示了S-SOFM的训练学习过程,该算法分为初始化、竞争、学习、重复迭代、得到获胜神经元等步骤。
在训练学习之前,首先需要用户设定好迭代周期T、学习率和输出节点的权重初始值等主要参数。针对输入的训练数据,设输入的数据样本的特征维度为N,共有L个训练样本,则输入样本空间X=[x1,x2,x3,…,xL]T,xi是样本空间中第i个输入的训练样本,i=1,2,…,L;每个训练样本都是一个N维特征向量,因此xi=[xi1,xi2,xi3,…,xiN]T。输出空间Y的节点数为M,则Y=[y1,y2,y3,…,yM]T,由于每一个节点都有一个对应的权重向量,因此输出节点的权重向量矩阵为W=[w1,w2,w3,…,wM]T,wk表示第k个输出神经元的权重向量值。由于每个输出神经元的权重向量初始值互不相等,因此wk的权重向量初始值是[0,1]区间内的随机值。此外,向量Φ表示每个节点被更新的频率,Φ=[φ1,φ2,φ3,…,φM]T,初始值为0,被用来平衡各输出节点的活跃度。η(t)是学习率参数,初值为η(0)[0<η(0)<1]。
在输入空间样本中随机选择一个样本xi作为输入神经元,Dk(t)则是当前时刻输入的特征向量xi(t)和第yk个输出节点的权重向量之间的相似性度量差值,公式如下:
}gsr}0086-1.jpg}/gsr}
根据上面的相似性度量算法,每一个输入的xi特征向量在输出的球体空间中都会有一个获胜神经元节点ywin,这是球体中和输入的xi具有最大相似度(最小距离)的节点,也被称为最佳匹配单元,表示为ywin=argmin{Dk}。
学习即调整获胜神经元节点及其相邻单元节点的权重向量值,也就是说,依据下列公式对输出的获胜神经元节点在邻域h(r)内的所有神经元权重值进行修正。
}gsr}0087-1.jpg}/gsr}
}gsr}0087-2.jpg}/gsr}
}gsr}0087-3.jpg}/gsr}
在上面的公式中,h(t)表示高斯拓扑邻域函数,r是有效的邻域半径。在t时刻,dr(yk,ywin)表示yk和获胜神经元节点ywin之间的距离,通常此距离越大,对权重的影响越小。η(t)是学习率参数,我们把它定义为如下形式:
}gsr}0087-4.jpg}/gsr}
T是可以迭代的最大次数,而t=1,2,…T,代表该节点当前的迭代次数,其中学习率参数的值在迭代中将不断地变小。
将下一个输入样本提供给SOFM的输入层,返回“学习”步骤,直至样本全部被提供一遍。如果学习过程满足由用户设置的“循环”参数(周期数)的停止条件,则训练过程将终止。
有关人工智能舞蹈交互系统原理与设计的文章

人是运动训练管理中最积极和潜力最大的因素。只有对运动训练中的人进行科学有效的管理,协调好各方关系,充分调动其积极性,才能更好地提高运动训练管理的效果。按照不同层次教练员与运动员之间的限额比例确定各项目教练员人数。运动训练计划实施中的指导,主要是训练职能部门或管理者督促下属管理者、教练员完成计划规定任务的训练管理活动或方式,以及运动训练过程的方法、手段的指导和帮助。......
2023-11-17

对于舞蹈动作识别,本章提出了一种无监督的、基于舞蹈姿态时空特征的S-SOFM识别方法,其特点表现为以下三个方面。基于第一章所提出的舞蹈特征提取模型,将舞蹈动作看作一系列姿态的时间序列,通过S-SOFM学习方法,将舞蹈动作转换为一个结构化的姿态空间,也就是说,把动作以离散姿态序列的形式映射到通过S-SOFM构建的球体输出空间中。每个节点代表一个动作姿态,每个动作都会拥有一条独特的“轨迹”,这样能够保证舞蹈动作识别的效果。......
2023-10-29
设计本章的迁移学习模型。将特征提取模块和分类器模块级联,即为本章设计的迁移学习模型。设置模型训练的超参数值。在初步训练分类器模块时,设置学习率为0.001,初步训练的轮数设为两轮。对整个模型进行微调训练。......
2023-06-29

任务描述二进制整数运算有自己的运算法则,与十进制整数运算比较起来相对简单。任务解析本任务要求掌握二进制整数的加减法及逻辑“与”运算,特别是逻辑“与”运算在计算机网络的学习中非常有用。意思是无论0、1,与0相“与”,结果为0;与1相“与”,则结果为原运算数。......
2023-11-21

基于上一章提出的舞蹈姿态的时空特征提取方法,针对形成的新的舞蹈动作特征集合,本章将利用S-SOFM构建一个有效的输出模型,对舞蹈动作进行聚类和分析,从而实现舞蹈动作的识别。图2-6 离散的姿态序列本书采用S-SOFM来构建输出模型。此外,由于保留了SOFM的特点,因此数据样本在重复训练分类之后生成的S-SOFM的各神经元节点之间的拓扑映射关系与原始输入样本一样。......
2023-10-29

机器学习一般根据处理的数据是否存在人为标注可分为监督学习和无监督学习。因此,监督学习的根本目标是训练机器学习的泛化能力。总之,机器学习就是计算机在算法的指导下,能够自动学习大量输入数据样本的数据结构和内在规律,给机器赋予一定的智慧,从而对新样本进行智能识别,甚至实现对未来的预测。机器学习的一般流程如图6-1所示。......
2023-06-28
运动频度指每周锻炼的次数。但由于运动效应和蓄积作用,间隔不宜超过3天。关于必要的运动频度,据日本池上晴夫的研究结果:一周锻炼1次时,锻炼效果不蓄积,肌肉痛和疲劳每次都发生,锻炼后1~3天身体不适,且易发生伤害事故;一周锻炼2次,肌肉疼痛和疲劳减轻,效果一点一点蓄积,但并不显著;一周锻炼3次,基本上是隔日锻炼,不仅效果可充分蓄积,也不产生疲劳;如果增加到一周4次或5次,效果也相应提高。......
2023-08-02

一般来说,运动训练管理体制的类型决定了其运作方式的类型,不同的运动训练管理体制其具体运作方式也是不同的。在政府主导型运动训练管理的运作方式下,政府对运动队实行全额拨款,运动队作为纯消耗型的事业单位,对资金的使用不承担任何责任。经过二十多年改革和发展,我国的运动训练管理出现了社会化运作方式和政府主导型运作方式以及两者合办的结合型运作方......
2023-11-17
相关推荐