PCIe设备必须支持L0s状态。L0s状态是一个低功耗状态,PCIe设备进入或者退出该状态不需要系统软件的干预,其状态转换由硬件控制完成。图8-13 L0s的接收状态机接收逻辑RX处于L0状态时,如果收到1个EIOS序列后,将进入Rx_L0s.Entry状态。接收逻辑RX在Rx_L0s.Idle状态中将持续监测接收链路,如果发现对端设备的发送逻辑TX退出“Electrical Idle”状态时,接收逻辑RX将进入Rx_L0s.FTS状态。......
2023-10-20
上节简要介绍了影响PCIe设备进行数据传递的因素,无论设计者采用什么样的设计方式,TLP在通过事务层、链路层和物理层时都会受到这些因素的影响。但是不同的设计方法依然会极大影响PCIe总线的使用效率。
本文中出现的Capric卡是一个很糟糕的设计,在这个设计中,并没有使用流水线机制来掩盖PCIe总线的延时,因此该卡通过PCIe总线进行DMA读时的效率并不高。
1.Capric卡DMA写的效率
在Capric卡中,DMA写操作由多个步骤组成,并由Capric卡的硬件逻辑和处理器的中断处理机制协调完成,其步骤如图12-11所示。
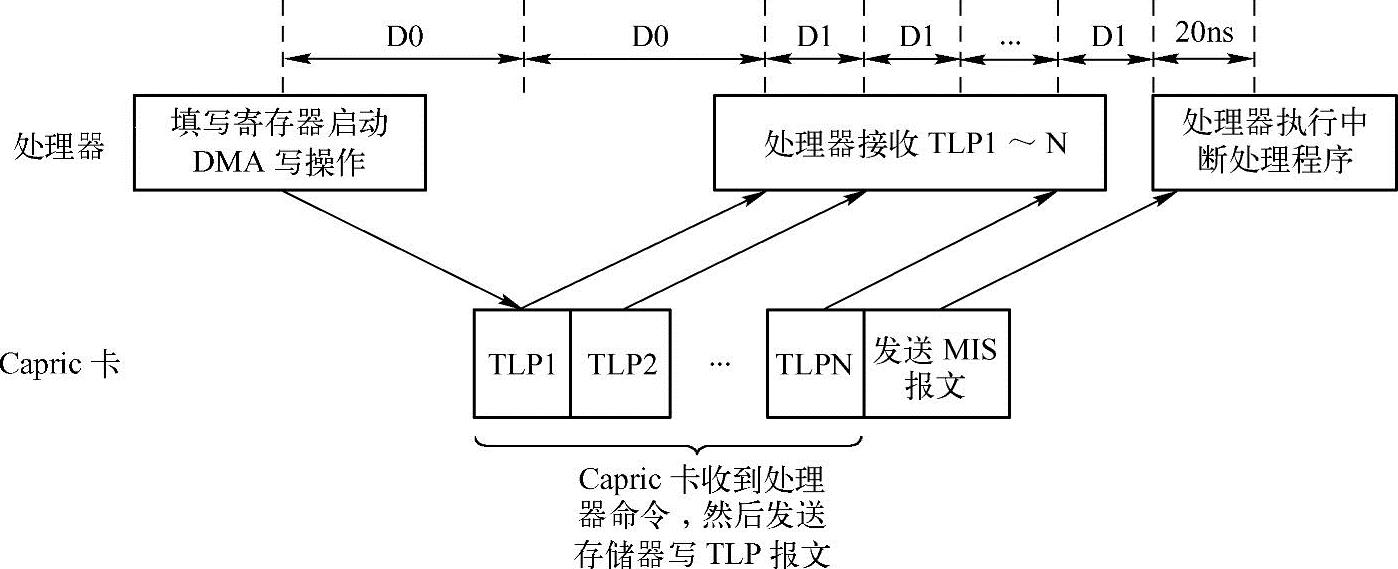
图12-11 Capric卡的DMA写过程
首先处理器填写Capric卡的WR_DMA_ADR、WR_DMA_SIZE和DCSR2寄存器,经过延时D0之后,这些命令陆续到达Capric卡。其中D0的大小与Capric卡连接在处理器系统中的位置相关,而与Capric卡的设计无关。如果Capric卡直接与RC相连接,则D0的值较小;如果Capric卡通过多级Switch之后再与RC连接,则D0较大。
Capric卡收到处理器的DMA写请求后,将向RC连续发送存储器写TLP,并由RC将数据写入到主存储器。Capric卡根据WR_DMA_SIZE寄存器的数值,将数据分解为多个存储器写请求TLP,其中每个存储器写请求TLP的有效负载不超过Max_Payload_Size参数,本节假设该参数的大小为128B。
假定Capric卡使用100MHz[105]的时钟,而内部总线宽度为64位,此时Capric卡内部总线的带宽可以达到800MB/s,该值非常接近×4PCIe链路所能提供的有效带宽;存储器写TLP使用3DW的报文头且不使用ECRC校验,而每个存储器写TLP的最大有效负载为128B(32DW)。因此在Capric卡中,一个存储器写TLP的最大长度为35DW,此时Capric卡需要使用18(实际值为17.5)个时钟周期才能将这个TLP发送出去,因此在Capric卡中D1的大小为180ns。
Capric卡将存储器写TLP发送完毕后,将向RC发送MSI报文,MSI报文也是一种存储器写TLP,Capric卡使用两个时钟周期,即20ns即可将该报文发送出去。RC在等待一段延时后,将陆续收到存储器写请求TLP1~N和MSI报文,这段延时为TLP从EP到RC的延时,约等于D0。
处理器收到MSI报文后,将执行中断处理程序,Capric卡的中断处理例程通过RC读取中断控制状态寄存器INT_REG,并结束整个DMA写操作。HOST处理器读取中断控制状态寄存器的开销绝对不能忽略,因为这个读取过程首先是RC发送存储器读请求TLP,当Cap-ric卡收到这个TLP后再向RC发送存储器读完成TLP,其访问延时为2×D0。
假设Capric卡一次DMA写的大小为X字节[106],则这次DMA写所需的时间Tdmaw如公式12-13所示。
Tdmaw=D0+D0+X/128×D1+20+2×D0 (12-13)
其中Tdmaw的值越小,Capric卡传送X字节的数据所需的时间也越短。但是以上公式并没有考虑Capric在DMA写过程中,因为数据缓冲不足而暂时中断存储器写TLP发送流水线的情况,而且忽略了中断处理例程所需的切换与执行时间。
由以上公式,可以发现当D0越大Tdmaw也越大。但是当X越大时,D0在Tdmaw中所占的比重越小,在一个处理器系统中,D0的大小是Capric卡无法控制的,该值的大小与Capric卡在处理器系统的位置和处理器系统的RC确定,属于系统延时,我们假设该值为250ns[107]。根据以上假设,可以利用公式12-13获得Capric卡DMA写的有效带宽,如表12-3所示。
表12-3 X的大小与DMA写有效带宽的关系

由表12-3所示,X越大,Capric卡的有效带宽也越高,因此适当提高X的大小将有效提高Capric卡DMA写的传送效率。
2.Capric卡DMA读的效率
在Capric卡中,DMA读的过程比DMA写过程略微复杂一些。因为DMA读是由两部分组成的,首先Capric卡向RC发起存储器读请求TLP;当RC从存储器获得数据后,再向Capric卡发送存储器读完成TLP,其实现过程如图12-12所示。(www.chuimin.cn)
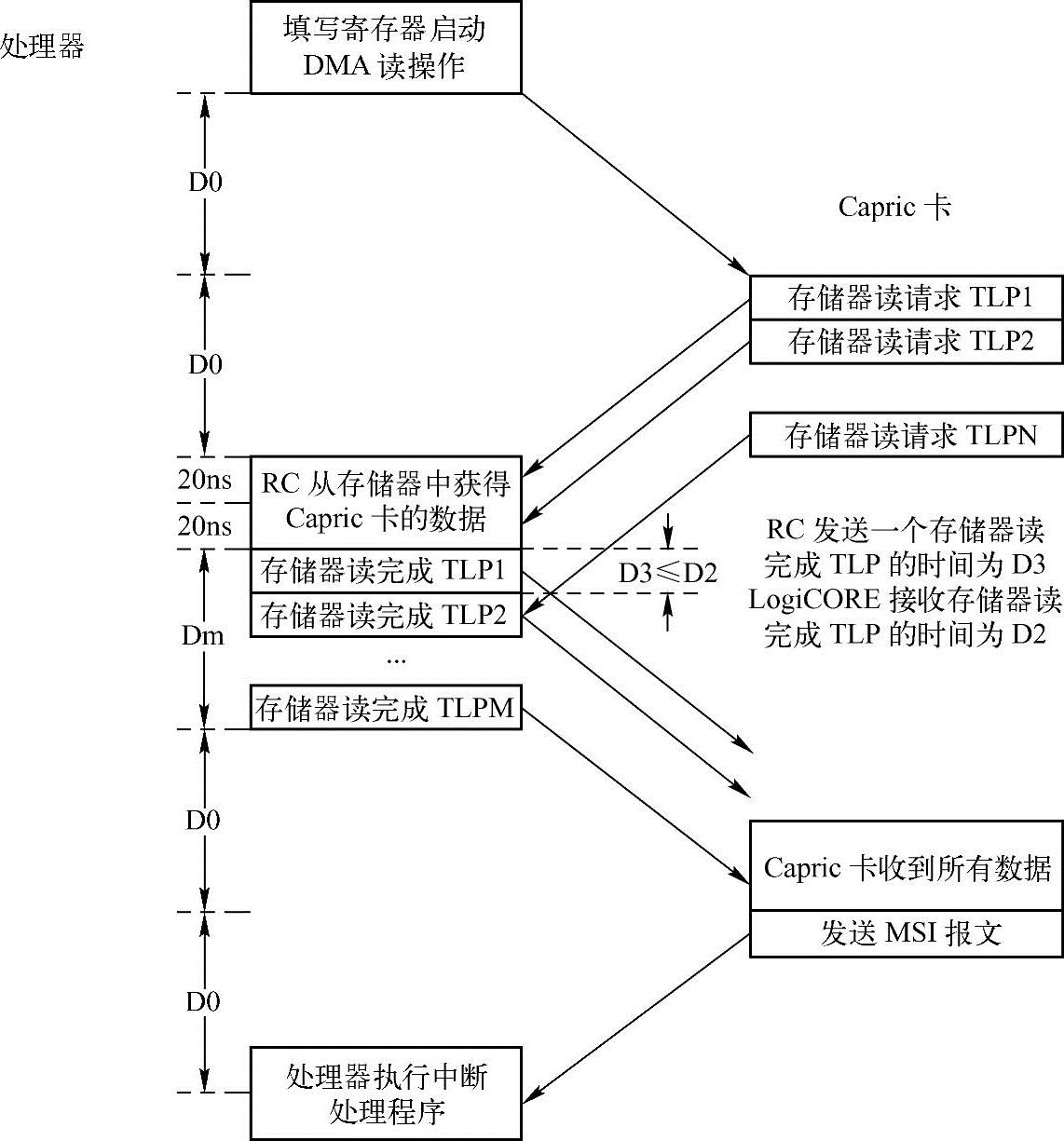
图12-12 Capric卡的DMA读过程
如上图所示,Capric卡的DMA读过程如下所示。
(1)首先处理器填写Capric卡的寄存器启动DMA读。
(2)Capric卡在等待D0这段延时后,收到这个命令,之后向RC提交存储器读请求TLP。假设Capric卡一共需要N个存储器读请求TLP才能发送完成整个请求,而且需要Dn这段时间才能将完成这些操作。而且存储器读请求TLP到达RC的延时也为D0。
(3)处理器在等待D0+D0这段延时后,将开始接收存储器读请求TLP,并从主存储器获得相应的数据,并组织存储器读完成报文发向Capric卡。RC从开始接收存储器读请求TLP到接收最后一个存储器读请求TLP的时间延时为Dn。其中Dn也与Capric卡发送全部存储器读请求的延时相同。
(4)RC收到来自Capric卡的存储器读请求TLP后,开始发送存储器读完成报文,其中Capric卡接收存储器读请求TLP与Capric卡发送存储器读完成TLP可以同步进行,因此Dn这段延时并不会被重复计算,而仅计算发送存储器读完成报文的流水准备时间,这段时间由两部分组成,Capric卡发送一个存储器读请求TLP的延时,和RC从主存储器中读取数据的延时。我们假定这两段延时都为20ns,因此流水准备时间为40ns。
(5)Capric卡经过D0这段延时后开始接收存储器读完成TLP,并经过Dm这段延时后将接收完毕所有来自RC的存储器读,并获得DMA读的所有数据。
(6)Capric卡发送MSI报文通知处理器DMA读完成。
(7)处理器经过D0这段延时后,收到MSI报文,并开始执行中断处理程序。如果这个中断处理程序仍然需要读取中断控制状态寄存器,则处理器需要2×D0这段延时时间之后才能完成Capric卡的DMA读。
其中D3延时为RC发送存储器读完成TLP所需要的时间,D3延时与RC的RCB参数相关。我们假设RC的RCB参数为64B,存储器读完成中的Payload为64B,而读完成报文头为12B;同时假设RC使用128b的数据总线,而且其总线频率为667MHz,此时RC发送的数据报文已经超过了Capric卡接收存储器读完成报文的速度,因此在分析中我们使用D2延时,其中D2为Capric接收存储器读完成报文的延时。Capric卡接收一个长度为84B的报文时间约为110ns(实际需要10.5个时钟周期)。因此Dm的计算方法如公式12-14所示。
Dm=D2×X/64=110×X/64 (12-14)
由以上分析,可以发现在PCIe总线中,Capric卡DMA读比DMA写的过程略微复杂。假设Capric卡一次DMA读的大小为X[108]字节,则这次DMA读所需的时间Tdmar如公式12-15所示。
Tdmar=2×D0+40+110×X/64+2×D0+2×D0 (12-15)
由以上公式,可以发现当D0越大时Tdmar也越大,但是当X越大时,D0在Tdmar中所占的比重越小。假设D0为250ns时,可以根据公式12-13获得Capric卡DMA读的有效带宽,如表12-4所示。
表12-4 X的大小与DMA读有效带宽的关系
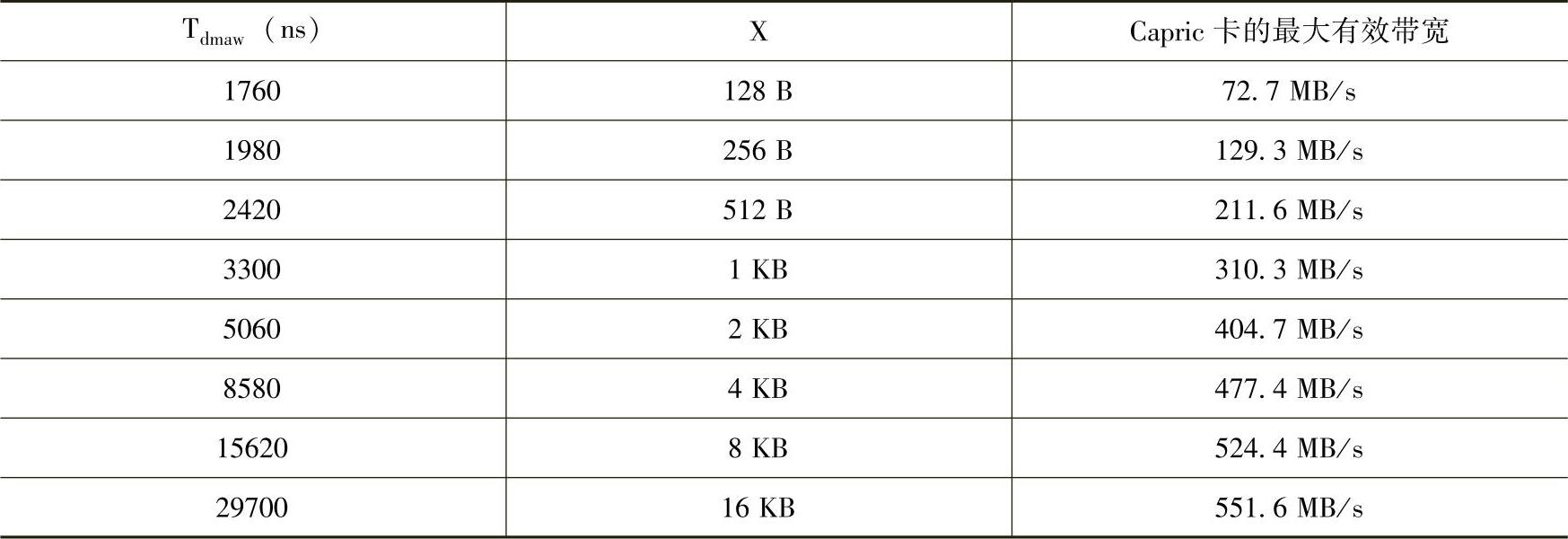
由表12-3和表12-4可以发现,Capric卡的DMA写的效率略高于DMA读的效率。以上有关Capric卡DMA读写效率是一个粗粒度的分析,其分析结果并没有考虑数据链路层、物理层和流量控制的开销,也没有考虑发送接收流水线中断的情况,是一个较为理想的结果。笔者的实测结果与表12-3和表12-4有些差距,因为在x86处理器系统中,D0延时时间远大于250ns。
有关PCI Express体系结构导读的文章

PCIe设备必须支持L0s状态。L0s状态是一个低功耗状态,PCIe设备进入或者退出该状态不需要系统软件的干预,其状态转换由硬件控制完成。图8-13 L0s的接收状态机接收逻辑RX处于L0状态时,如果收到1个EIOS序列后,将进入Rx_L0s.Entry状态。接收逻辑RX在Rx_L0s.Idle状态中将持续监测接收链路,如果发现对端设备的发送逻辑TX退出“Electrical Idle”状态时,接收逻辑RX将进入Rx_L0s.FTS状态。......
2023-10-20

而这个PCI桥的Secondary Bus在接收Dock设备的请求时仍然使用正向译码方式。PCI桥使用的正向译码方式与PCI设备使用的正向译码方式有所不同。值得注意的是,PCI总线并没有规定HOST主桥使用正向还是负向译码方式接收这个存储器读写总线事务,但是绝大多数HOST主桥使用正向译码方式接收来自下游的存储器读写总线事务。......
2023-10-20

PCIe总线进行链路训练的主要目的是初始化PCIe链路的物理层、端口配置信息、相应的链路状态,并了解链路对端的拓扑结构,以便PCIe链路两端的设备进行数据通信。此时该PCIe设备在进行链路训练时,必须通知对端链路该设备实际使用的链路状态。此外PCIe总线在链路训练过程中,还需要确定数据传送率。PCIe总线进行链路训练时,需要进行RC或者Switch的Link Number和Lane Number的初始化,在第8.2节中将详细介绍这些内容。......
2023-10-20
而桥设备的主要作用是管理下游的PCI总线,并转发上下游总线之间的总线事务。PCI总线规范将PCI主从设备统称为PCI Agent设备。PCI规范也没有规定如何设计HOST主桥。在PCI总线中,还有一类特殊的设备,即桥设备。本书重点介绍PCI桥,而不介绍其他桥设备的实现原理。PCI桥的出现使得采用PCI总线进行大规模系统互连成为可能。其中对PCI设备配置空间的访问可以从上游总线转发到下游总线,而数据传送可以双方向进行。......
2023-10-20

存储器读写请求TLP的格式如图6-8所示。在存储器读写和I/O读写请求的第3和第4个双字中,存放TLP的32或者64位地址。存储器、I/O和原子操作读写请求使用的TLP头较为类似。此时与这个存储器读请求TLP对应的读完成TLP中不包含有效数据。......
2023-10-20
填写RD_DMA_SIZE寄存器,以字节为单位。填写DCSR2寄存器的mrd_start位,启动DMA读。等待DMA读完成中断产生后,结束DMA读。从硬件设计的角度来看,DMA读过程比DMA写过程复杂。Capric卡的1次DMA读操作使用两种TLP报文,并通过发送部件和接收部件协调完成。如果一次DMA读请求的数据大于512B[84]时,DMA控制逻辑需要发送多个存储器读请求TLP给RC,而且在DMA读操作中需要进行数据对界。DMA读操作的详细实现过程见第12.2.2节。......
2023-10-20

目前虚拟化技术在处理器体系结构中,已经占据一席之地。本章所强调的虚拟化技术是指在一个处理器系统[109]中运行多个虚拟处理器系统的技术。因此处理器需要为虚拟化环境设置专门的硬件,以支持多个虚拟处理器系统在一个物理环境中的资源共享。虚拟化技术的核心是通过VMM集中管理物理资源,而每个虚拟处理器系统通过VMM访问实际的物理资源。本章重点关注的是VMM对外部设备的管理,而在外部设备中重点关注对PCI设备的管理。......
2023-10-20

在一段程序中,存在大量的分支预测指令,因而在某种程度上增加了指令Fetch的难度。但是分支预测单元并不会每次都能正确判断分支指令的执行路径,这为指令Fetch制造了不小的麻烦,在这个背景下许多分支预测策略应运而生。在PowerPC处理器中,条件转移指令“bc”表示Taken;而“bc-”表示Not Taken。BTB的功能相当于存放转移指令的Cache,其状态机转换也与Cache类似。转移指令B执行完毕后,将实际执行结果Rc更新到BHR寄存器中,并同时更新PHT中对应的Entry。......
2023-10-20
相关推荐