在这个过程中,FBI探员不仅会使用一些必要的调查和测试工具还会借助于读心术来确认他人话语的真实性。FBI将自己的调查结果呈报给政府,这名官员得到了应有的制裁。于是FBI探员就把引起这名高层面部变化的几个名字进行了重点调查,最终查出了真相。不仅仅是这些,还有许多的方式都是FBI探员运用读心术的具体办法,他们从心理学的角度出发,进行读心术的研究和分析,并在不断地发展着得出的结论,使其成为了一套完整的破案方法。......
2023-12-05
与DMA写模块相比,DMA读模块的逻辑设计较为复杂。在PCIe总线中,存储器写TLP使用Posted总线传送方式,实现DMA写操作只需要使用存储器写TLP即可。而PCIe总线使用Split总线传送方式进行存储器读操作。因此一个DMA读过程由EP向RC发送“存储器读请求TLP”,之后再由RC使用“存储器读完成TLP”将数据传递给EP。
当软件启动DMA读操作后,DMA控制逻辑将根据需要读取数据区域的大小,决定发送存储器读请求TLP的个数,如果所读取数据区域的实际长度超过Max_Read_Request_Size参数[89]时,DMA控制逻辑需要进行拆包处理,向RC发送多个存储器读请求TLP,这些存储器读请求TLP将使用不同的Tag。
当RC收到这些存储器读请求TLP后,将使用存储器读完成TLP,将数据传递给Capric卡。其中一个存储器读请求TLP(Tag不同的报文)可能对应多个存储器读完成TLP,而且这些存储器读完成TLP可以乱序到达。
在Capric卡的DMA读模块的设计中,首先需要进行拆包处理,其次需要合理地管理Tag资源,而最值得注意的是对存储器读完成TLP的乱序处理。为此在Capric卡中设置了一个单向循环链表tag_queue,以便Capric卡发送存储器读请求TLP,进行Tag资源的管理,并处理存储器读完成TLP的序。
1.tag_queue
Capric卡的DMA读模块使用了一个单向循环队列tag_queue,当然设计者也可以使用其他逻辑实现同样的功能。实际上对于Capric卡而言,设置这样的循环队列是奢侈的,因为Capric卡仅实现了基本的DMA读写操作。该循环队列实际上是为笔者的另一个设计,即Cornus卡[90]准备的。
在tag_queue队列中,设置了头尾指针,分别为tag_front和tag_rear,Capric卡使用8位[91]寄存器存放这两个指针。该队列的每一个Entry对应一个tag资源,其Entry号与Tag号一一对应。DMA读模块从tag_rear指针获得当前可以使用的tag资源(相当于将获得的tag字段加入tag_queue中),并从tag_front指针处释放tag资源(相当于从tag_queue的头部释放资源),在tag_front和tag_rear之间的Entry保存正在使用的tag资源。tag_queue队列的组成结构如图12-3所示。
在Capric卡复位时,tag_front与tag_rear指针同时指向Entry 0,此时tag_queue为空。当Capric卡需要使用tag资源时,首先判断tag_queue是否为满,如公式12-6所示。
(tag_rear+1)mod256=tag_front(12-6)
当tag_queue队列不满时,Capric卡可以从tag_queue中获得tag资源,其值等于tag_rear,然后将tag_rear更新为(tag_rear+1)mod256(相当于将获得的tag加入到tag_queue队列中)。当Capric卡释放tag资源时,需要判断tag_queue是否为空,如公式12-7所示。
tag_rear=tag_front(12-7)
在Capric卡中,到达的存储器读完成TLP因为乱序的原因,其tag字段不一定与tag_front相等。Capric卡错误处理逻辑需要判断到达的存储器读完成TLP的tag字段是否在tag_front和tag_rear之间(在图12-3d中,阴影部分的Entry在当前tag_queue中有效),其判断条件如公式12-8所示。
(tag-tag_front)mod256<(tag_rear-tag_front)mod256(12-8)
在Cornus卡中,tag_queue队列的Entry由许多字段组成,在这些字段中“L”和“U”位对于Capric卡有意义。其中U为Used位,当该位为1时,表示对应Entry正在被使用,为0时表示没有被使用;而L为Last位,当该位为1时,表示对应Entry保存DMA操作最后一个存储器读请求TLP。这些位的详细解释见下文。

图12-3 循环队列tag_queue的组成结构
a)tag_queue的初始化 b)tag_queue为空 c)tag_queue为满 d)tag_queue中的有效Entry
2.Capric卡发送存储器读请求TLP
Capric卡发送存储器读请求TLP与发送存储器写TLP的步骤较为类似,只是存储器读请求不含有Data Payload,存储器读请求TLP的格式如图6-8所示。与存储器写请求TLP相比,存储器读报文多了两个字段分别为Requester ID字段和Tag字段,这两个字段合称为Transaction ID字段,该字段的结构如图6-9所示。
从第6.2.1节中,可以获知存储器读请求TLP使用地址路由方式,Capric卡将存储器读请求TLP发送给RC时,并不需要使用Transaction ID字段进行ID路由。但是存储器读完成TLP需要使用ID路由方式进行传送,因而需要使用Capric卡的Transaction ID字段将存储器读完成TLP发送给Capric卡。
在PCIe总线中,每一个数据传送都有唯一的Transaction ID,Transaction ID由Requester ID和Tag字段组成,其中Requester ID由HOST处理器在系统初始化时设置。Capric卡需要记录这个Requester ID,以便传送存储器读请求TLP。
在存储器读请求TLP中其他字段的设置与存储器写请求TLP类似,这些字段的设置参见上文。其中存储器读请求TLP的Fmt字段为0b00/0b01,表示使用3DW/4DW的TLP头,而且不带数据;而Type字段与存储器写请求TLP的type字段相等,都为0b0000。在PCIe总线中,存储器写报文一定带有数据,而存储器读请求一定不带数据,这是PCIe总线区分存储器读请求TLP和存储器写TLP的方法。在设计中,Capric卡使用4DW的读请求TLP头,因为Capric卡内部使用64b数据总线,使用4DW的报文头便于对界处理;而存储器读完成报文只能使用3DW的报文头,这为Capric卡的设计也带来了一些困难。
在存储器读请求TLP中,需要重点处理的字段是Tag。在PCIe总线中,每个设备都有唯一的Requester ID,而且每一次数据传送使用不同的Transaction ID,在一次数据传送没有完成之前,其他数据传送不能使用相同的Transaction ID。在PCIe总线中,使用Tag字段区分不同的Transaction ID,因为对于同一个PCIe设备发出的TLP,Requester ID字段都是相同的,只有Tag字段不同。
当Capric卡向RC发送存储器读请求TLP时,将从tag_queue中选择一个未用的Tag资源;当Capric卡收齐与“存储器读请求TLP”对应的“存储器读完成TLP”[92]后,将释放这个Tag资源,之后其他存储器读请求TLP可以使用这个Tag。
为此Capric卡需要使用一组数据缓冲维护这个Tag字段。在PCIe总线中,Tag字段为5或者8位,如果使能了Phantom功能,一个PCIe设备可以使用更多的Tag资源,详见第4.3.2节。在Capric卡中,并没有使能Phantom功能,而且使用的Tag字段为8位,即Device Capa-bility寄存器的Extended Tag Field Supported位为1,该寄存器的详细描述见第4.3.2节。
Capric卡使用tag_rear指针从tag_queue队列中获得未用的tag资源,并设置tag_queue中对应Entry的L和U位。Capric卡发送存储器读请求TLP时,首先需要判断本次DMA读操作一共需要向RC发送几个存储器读请求TLP。在Capric卡中,一次DMA读可以使用的最大传送单位为2047B,该值超过Capric卡的Max_Read_Request_Size参数(512B),因此Capric卡发送存储器读请求TLP时需要进行拆包操作。
如果Capric卡读取A(A31A30...A1A0)~B(B31B30...B1B0)这段数据区域时,需要首先计算每段数据区域的实际长度M,该长度的计算与公式12-4相同。如果M小于或等于512B,需要继续检查这段数据区域是否超过4KB边界,如果超过需要将这段数据区域分为A~Tail4096(A)和Head4096(B)~B这两段数据区域进行读操作。
如果M大于512B,Capric卡需要进行拆包处理,将A~B这段数据区域分割为若干个数据区域,其中每一段数据区域的Length字段不超过0x80,而且为512B对界。Capric卡使用的拆包方法如下所示。
第1个存储器读请求TLP对应的数据区域:A31A30...A1A0~Tail512(A)
第2个存储器读请求TLP对应的数据区域:Head512(A+512)~Tail512(A+512)
…
第n个存储器读请求TLP对应的数据区域:Head512(A+n×512)~Tail512(A+n×512)
…
最后1个存储器读请求TLP对应的数据区域:Head512(B)~B31B30...B1B0
以上这些数据区域的M都小于0x80,而且都不会跨越512B边界,因此也不可能超过4KB边界。使用以上拆包方法,Capric卡可以获得若干个M小于或等于0x80的数据区域,因此Capric卡可以使用一个存储器读请求从主存储器获得以上每段数据区域对应的数据。Capric卡使用4DW的TLP头,其格式如图12-4所示。
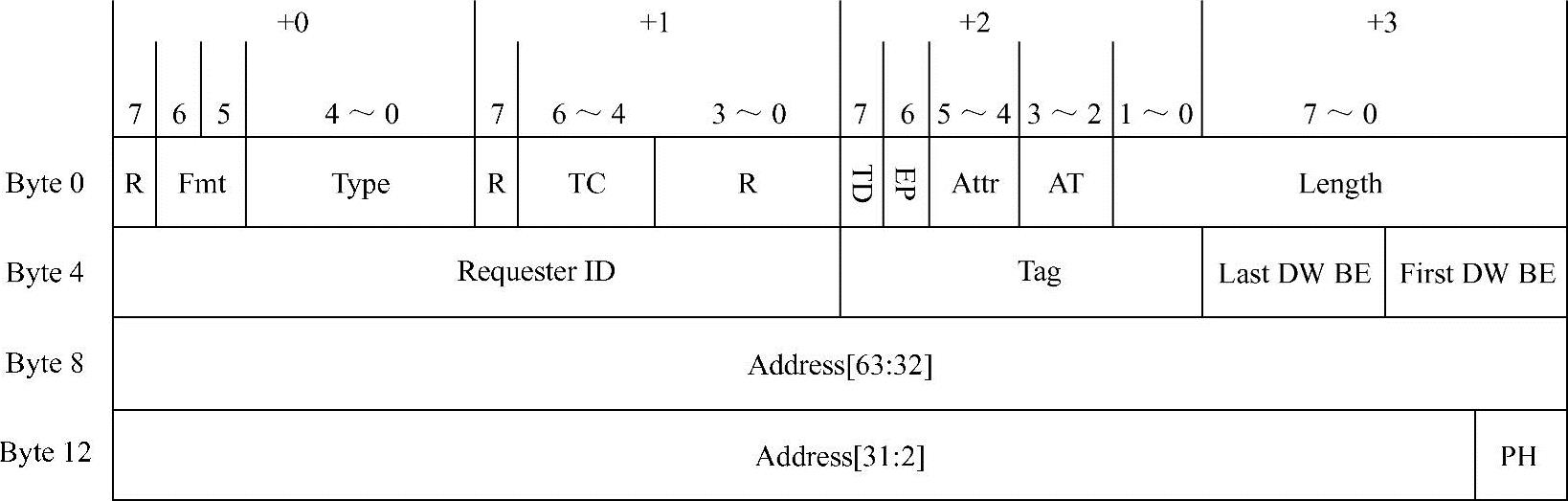
图12-4 存储器读请求TLP头格式
Capric卡向RC发送这些存储器读请求TLP的详细步骤如下。
(1)组织存储器读请求TLP,其中Byte 0中的字段、First/Last DW BE字段和Address字段与存储器写请求TLP的对应字段相同,本小节对此不做详细描述。而Requester ID字段由Host处理器在初始化时设置。
(2)Capric卡从tag_queue队列中获得tag字段,首先通过公式12-6判断tag_queue队列是否有可用tag资源,如果没有则循环等待公式12-6成立;如果有可用tag,则继续。在Capric卡中,Address[63:2]较小的存储器读请求使用的Tag字段也较小。
(3)当前存储器读请求使用tag_rear作为tag字段,同时置tag_queue[tag_rear].U为1,表示当前Entry已被使用。
(4)在一次DMA读操作时,Capric卡可能需要进行拆包操作。如果当前存储器读请求TLP是最后一个TLP,则将tag_queue[tag_rear].L位置为1,否则置为0。
(5)将tag_rear赋值为(tag_rear+1)mod256,然后发送该存储器读请求TLP。如果L位为0时转(1),表示与当前DMA操作对应的存储器读请求TLP还没有发送完毕;否则结束存储器读请求报文的发送。
Capric卡发送存储器读请求TLP时,还需要考虑一个细节问题。在PCIe总线中,EP为CplH和CplD提供的Credit为0,即Infinite Credit,详见第9.3.2节。这意味着EP每发送一个存储器读请求,必须为对应的存储器读完成的报文头和数据预留缓冲。
假设Capric卡连续向RC发送了256个存储器读请求TLP,其中每个存储器读请求TLP访问的数据区域为512B,而在RC发送的存储器读完成TLP中一次只能携带64B。此时即便不考虑对界的问题,Capric卡也需要为存储器读完成预留较大的缓冲空间,该空间由两部分组成,如下所示。
(1)预留存储器读完成TLP头的空间大小为8192B(256×512×4/64)。
(2)预留存储器读完成TLP数据的空间大小128KB(256×512 B)。
在硬件设计中,为了提高DMA读的数据传送效率,还可以使能Phantom功能,此时EP能够发送的存储器读请求TLP更多。如果EP经过若干级Switch后,才能到达RC,此时RC可能正在处理其他EP的存储器读请求而不会立即处理这些存储器读请求,此时该EP可能长时间不能收到存储器读完成TLP,从而无法释放预留的数据缓冲。因此EP可能会因为没有数据缓冲,而无法继续发送存储器读请求TLP。
实际上,硬件为存储器读完成报文预留的数据缓冲是有限的,一般不会预留136KB大小的空间,在LogiCORE中,为CplH预留的缓冲单元为33~36个,而为CplD中的数据预留的缓冲为2176~2304B。
由此可以发现如果RC没有及时地将存储器读完成TLP发送回来,Capric卡最多在连续发送33个存储器读请求后(假设存储器读请求使用4DW的报文头),就因为无法为存储器读完成的报文头提供足够的缓冲而不能继续发送;此外如果每个存储器读请求所访问的数据区域都是512B,Capric卡最多在连续发送4个这样存储器读请求后,就不能继续发送这样的存储器读请求,从而造成发送流水线的中断。
由此可以发现,在LogiCORE中,由于预留的缓冲有限,Capric卡在使用PCIe总线要求的Infinite Credit机制时,将因为预留缓冲不足而造成流水线的中断。为此LogiCORE提供了三种流量控制机制,这三种流量控制机制在重构LogiCORE时选择使用,系统软件不能通过修改寄存器动态配置这些流控方式。
(1)Infinite Credit
该方式与PCIe总线规范兼容。如果Capric卡使用Infinite Credit方式,当LogiCORE内部的接收缓冲不足时,Capric卡不能向RC发送存储器读请求报文。根据上文的讨论,由于LogiCORE内部的接收缓冲不足,因此使用该方式在某种程度上,将造成DMA读流水线的中断,从而影响DMA读的效率。
(2)One Posted/Non-Posted Header
该方式与PCIe总线规范不兼容,使用这种方式时,EP每次为上游端口发送的Posted请求和Non-Posted请求提供最小的Credit,相当于EP每一次只能发送一个存储器读请求TLP,而得到与之对应的存储器读完成TLP后,再提交下一个存储器读请求TLP。使用这种方法将严重影响DMA读的效率。LogiCORE提供的这种方法可能是用于调试目的。在正常情况下设计者不应该使用这种方式。
(3)Non-Infinite Credit
该方式与PCIe总线规范不兼容,使用这种方式时,EP并没有给上游端口提供无限量的Credit,而是根据预留接收缓冲的实际使用情况,为上游端口提供Credit。Capric卡采用这种方式,发送存储器读请求TLP时,并不会为存储器读完成TLP事先预留接收缓冲,从而在发送存储器读请求TLP时,并不会因为接收缓冲不足而被中断,因此提高了Capric卡发送存储器读请求TLP的效率。
LogiCORE在接收存储器读完成报文时,将根据预留缓冲的实际大小为对端提供Credit。虽然采用这种方法与PCIe总线规范要求的Infinite Credit并不兼容。但是使用这种方法避免了在发送存储器读请求时,因为接收缓冲不足而引发的流水线中断,从而Capric卡可以连续发送多个存储器读请求,无论是否具有足够的接收缓冲。
而Capric卡将以较快的速度从LogiCORE的预留缓冲中获得数据,因此在多数时间里,不会因为预留缓冲被对端设备耗尽而引发接收流水线的中断。因此在实际设计中,Capric卡使用了这种流量控制方式。(www.chuimin.cn)
3.Capric卡接收存储器读完成TLP
在PCIe总线中,EP发出的存储器读请求可以超越之前的存储器读请求,而且当存储器完成报文使用的Transaction ID不同时,存储器读完成TLP也可能超越之前的存储器读完成TLP,这将造成存储器读完成TLP乱序到达Capric卡。
Capric卡必须注意处理这个乱序问题。下面举例说明这个序的问题,假设Capric卡向处理器的0x1000~0x11FF这段数据区域发送存储器读请求TLP,RC将通过存储器读完成TLP向Capric卡传递数据。如果这个RC使用的RCB为64B,则RC可以使用4个存储器读完成TLP发送这些数据,如图12-5所示。

图12-5 使用一个存储器读TLP对0x100~0x11FF进行DMA读操作
其中第1个存储器读完成TLP的数据来自0x1000~0x107F这段数据区域;第2个存储器读完成TLP的数据来自0x1080~0x10FF这段数据区域;第3个存储器读完成TLP的数据来自0x1100~0x117F这段数据区域;而第4个存储器读完成TLP的数据来自0x1180~0x11FF这段数据区域。在这种情况下,存储器读完成报文将按序到达Capric卡,从而并不会对Capric卡的硬件逻辑造成影响。
如果Capric卡使用2个存储器读请求TLP向处理器的0x1000~0x11FF这段数据区域发起存储器读请求。其中第1个存储器读请求TLP(tag 0)向处理器的0x1000~0x10FF这段数据区域发起存储器读请求,而第2个存储器读请求TLP(tag 1)向处理器的0x1100~0x11FF这段数据区域发起存储器读请求。此时来自RC的存储器读完成报文可能乱序到达Capric卡,如图12-6所示。
此时RC依然使用4个存储器读完成TLP向Capric卡发送这些数据,但是由于序的问题,这4个存储器读完成TLP可能以2种不同的顺序发向Capric卡。当然RC还可以以其他顺序向Capric卡发送这些TLP,本节并不列出所有可能的顺序。
(1)第1种序
●第1个存储器读完成TLP的数据来自0x1000~0x107F这段数据区域(tag 0)。

图12-6 使用两个存储器读TLP对0x100~0x11FF进行DMA读操作
●第2个存储器读完成TLP的数据来自0x1080~0x10FF这段数据区域(tag 0)。
●第3个存储器读完成TLP的数据来自0x1100~0x117F这段数据区域(tag 1)。
●第4个存储器读完成TLP的数据来自0x1180~0x11FF这段数据区域(tag 1)。
(2)第2种序
●第1个存储器读完成TLP的数据来自0x1100~0x117F这段数据区域(tag 1)。
●第2个存储器读完成TLP的数据来自0x1000~0x107F这段数据区域(tag 0)。
●第3个存储器读完成TLP的数据来自0x1180~0x11FF这段数据区域(tag 1)。
●第4个存储器读完成TLP的数据来自0x1080~0x10FF这段数据区域(tag 0)。
这个乱序问题为Capric卡的DMA读机制的设计带来了不小的麻烦。因为在“第2种序”的情况下,先发出去的存储器读请求TLP,后接收到与之对应的存储器完成报文。不过值得庆幸的是,对于一个存储器读请求TLP,其对应的存储器完成报文虽然也有多个,但是这些报文将以地址顺序先后到达。如向0x1000~0x10FF这段数据区域发送的存储器读请求,其存储器完成报文虽然被分解为两个,但一定是传送0x1000~107F这段区域的存储器读完成TLP率先到达,而传送0x1080~0x10FF这段区域的存储器读完成TLP随后到达。
在Capric卡的设计中必须考虑这个乱序问题,因为Capric卡进行DMA读操作时,所读取的数据区域可能超过Max_Read_Request_Size参数,此时Capric卡对这段数据区域进行DMA读时,必须向RC发出多个存储器读请求TLP,参见上文。
与Capric卡发送存储器读请求TLP相比,Capric卡处理存储器读完成TLP的过程更为复杂。当Capric卡收到来自RC的存储器完成报文后,需要进行一系列检查。存储器读完成TLP的格式如图12-7所示。
Capric卡接收到存储器读完成TLP后,首先需要检查报文头。其中Fmt字段必须为0b010,Type字段必须为0b01010。除此之外Capric卡还需要进行以下检查。
(1)存储器读完成TLP的Requester ID字段必须与Capric卡的Requester ID字段相等。否则该存储器读完成TLP被认为是“Unexpected Completion”报文,Capric卡需要丢弃该存储器读完成TLP,并将ERR寄存器的UC位置1。
(2)检查存储器读完成TLP的Status字段,如果Status字段不为0b000,则表示接收到的TLP出现错误。如果Status字段为0b001或者0b100时,Capric卡需要丢弃该存储器读完成TLP,并将ERR寄存器的相应位置1。
(3)检查存储器读完成TLP的Tag字段,确认当前报文是否与已经发出的存储器读请求TLP对应,检查方法如公式12-8所示。

图12-7 存储器读完成TLP
(4)此外Capric卡还需要检查EP位,TD位、TC字段和Attr字段。
Capric卡的接收部件成功完成这些检查之后,将从存储器读完成TLP中获取数据。PCIe总线规定,一个存储器读请求TLP,可以对应多个存储器读完成TLP。这为Capric卡的设计带来了一定的困难,为此Capric卡需要将存储器读完成TLP全部收齐后,才能释放相应的Tag资源,最后将tag_queue对应Entry的U位和L位清零。
存储器读完成报文虽然可能有多个,但是这些报文将以地址顺序先后到达。因此Capric卡首先需要分析Tag字段,从而确定当前存储器读完成TLP与哪个存储器读请求TLP对应。其中第1个存储器读完成TLP与存储器读请求TLP起始地址对应,之后的存储器读完成TLP将地址顺序依次到达。假定向[A31A30...A1A0~B31B30...B1B0]这段数据区域发起存储器读请求时,RC将发送多个存储器读完成TLP,并以下列顺序到达。
[A31A30...A1A0~Tail64(A31A30...A1A0)]
[Head64(A31A30...A1A0+64)~Tail64(A31A30...A1A0+64)]
…
[Head64(A31A30...A1A0+n*64)~Tail64(A31A30...A1A0+n*64)]
…
[Head64(B31B30...B1B0)~B31B30...B1B0]
当然RC也可能向Capric发送一个存储器读完成TLP,传递[A31A30...A1A0~B31B30...B1B0]数据区域中的所有数据。无论这些存储器读完成TLP以什么样的形式到达,Cap-ric卡都需要正确接收这个存储器读完成TLP。
Capric卡首先分析存储器读完成TLP的Length字段,在该字段中存放当前存储器读完成TLP的长度,值得注意的是Length字段所存放的长度,可能超过这个存储器完成报文的包含的有效数据长度,因为地址A31A30...A1A0很可能不是1DW对界,而Length字段存放的最小数据单位为1DW。此时Capric卡必须正确识别存储器读完成TLP中Data0(即第一个双字)中包含的有效数据,以及Data(Length-1)(即最后一个双字)中包含的有效数据。
在RC发送给Capric卡的多个存储器读完成TLP中,只有第1个存储器读完成TLP所对应的存储器区域的起始地址可能不是DW对界;而如果存在其他存储器读完成TLP,那么这些报文所对应存储器区域的起始地址至少是64B对界的,也可能是128B对界的[93]。
但是存储器读完成TLP并不含有First DW BE字段,此时Capric卡需要使用存储器读完成TLP中的Lower Address字段识别Data0中的有效字节。
在第1个存储器读完成TLP中,Lower Address[1:0]=A1A0,对于其他存储器读完成TLP,其Low Address[1:0]=0b00。因此通过Lower Address字段,可以识别Data0中第一个有效数据,即Data0[A1A0]为第一个有效数据。
存储器读完成TLP并没有设置Last DW BE字段,Capric卡需要使用Byte Count和Lower Address字段联合识别Data(Length-1)中的有效数据。如果当前存储器读完成TLP不是最后一个TLP,那么其Data(Length-1)中的数据全部有效。因为PCIe总线规定,如果RC为1个存储器读请求TLP发送多个存储器读完成TLP,如果这个存储器读完成TLP不是最后一个报文,那么其结束地址必须64B对界。
如果当前存储器读完成TLP不是第1个TLP,那么其Lower Address[1:0]=0b00。在这两种情况下,Data(Length-1)中的有效数据较易计算。但是有一个特例情况,就是RC只发出了一个存储器读完成TLP给Capric卡,此时这个TLP既是第一个存储器读完成TLP也是最后一个存储器读完成TLP。但是无论是上述哪种方式,依然存在计算Data(Length-1)中的有效数据的通用方法,如公式12-9所示。
0bX1X0=LowAddress[1:0]+ByteCount[1:0]-0b01 (12-9)
其中Data(Length-1)[X1X0]为存储器读完成TLP中最后一个有效数据。Capric卡计算完毕存储器读完成TLP的Data0和Data(Length-1)中的有效数据后,还需要判断当前存储器读完成TLP是不是RC发出的最后一个与当前Tag对应的存储器读完成TLP。为直观起见,以图12-8为例说明如何计算当前存储器读完成TLP是否为最后一个报文。

图12-8 最后一个存储器读完成TLP的判断方法
如上图所示,Start Address为存储器读完成TLP的起始地址,而End Address为存储器读完成TLP的结束地址。在一个存储器读完成TLP中,我们无法得到Start Address和End Ad-dress的确切的数值,因为存储器读完成TLP不包含Address字段,但是可以得到阴影A和阴影B的大小。其中阴影A的大小为Low Address[1:0],而阴影B的大小为0b11-0bX1X0。
如果当前TLP的Byte Count字段加上阴影A和B的大小与Length×4相等,即公式12-10成立时,该TLP为RC发给Capric卡的最后一个存储器读完成TLP。
(Byte Count+Low Address[1:0]+0b11-0bX1X0)=Len gth≪2 (12-10)
请读者重新阅读第6.3.2节,深入理解Byte Count参数的含义,以加深对公式12-10的理解。在Capric卡的硬件设计中,需要使用该公式识别最后一个到达的存储器读完成TLP。
在Capric卡接收到最后一个存储器完成TLP之后,将完成一次存储器读请求。当最后一个存储器读请求完成后,将完成一次DMA读操作。Capric卡接收存储器读完成TLP的详细步骤如下所示。
(1)首先进行报文检查。如果通过这些检查后,将从存储器读完成报文中获得数据填入相应SRAM的对应区域中。
(2)DMA读逻辑通过存储器读完成TLP的Tag字段在tag_queue中查找对应的Entry。如果当前存储器读完成是最后一个TLP,将该Entry的U位清零。此时如果该Entry的L位为1,表示本次DMA读结束,并向处理器提交中断请求,同时清除L位,并置相应的中断状态寄存器。Cormus卡支持多路并发的DMA读操作,因此需要在Entry中设置L位。
(3)DMA读模块可能会更新tag_front指针,如果Tag字段不等于tag_front指针,读模块不能更新tag_front,而仅是将对应Entry的U位清零;如果相同则将tag_front更新为(tag_front+1)mod 256,同时将U位清零。
(4)之后DMA读模块继续判断tag_queue[tag_front]的U位是否为0。如果该位为0,将tag_front更新为(tag_front+1)mod 256,然后继续判断Tag_queue[tag_front]的U位是否为0,直到公式12-7成立,或者Tag_queue[tg_front]的U位为1。
有关PCI Express体系结构导读的文章

在这个过程中,FBI探员不仅会使用一些必要的调查和测试工具还会借助于读心术来确认他人话语的真实性。FBI将自己的调查结果呈报给政府,这名官员得到了应有的制裁。于是FBI探员就把引起这名高层面部变化的几个名字进行了重点调查,最终查出了真相。不仅仅是这些,还有许多的方式都是FBI探员运用读心术的具体办法,他们从心理学的角度出发,进行读心术的研究和分析,并在不断地发展着得出的结论,使其成为了一套完整的破案方法。......
2023-12-05

本章技能考查电容器的识读;用指针式万用表对电容器的质量进行检测。电容器的色标法与电阻相同。电容量为10~100μF选用R×1 k挡。注意:对于耐压低于9 V的电容器,不能用R×10 k挡来检测。此时的阻值便是电容器的漏电电阻值。......
2023-10-21

在x86处理器和PowerPC处理器中,PCI设备对“不可Cache的存储器空间”进行DMA读写的过程并不相同。在x86处理器中,PCI设备向不可Cache的存储器空间进行读操作时,CPU也必须进行Cache共享一致性操作,而这种没有必要的Cache共享一致性操作将影响PCI总线的传送效率。此时PowerPC处理器不会在FSB总线中进行Cache一致性操作,即忽略FSB总线事务的Snoop Phase。PCI设备进行DMA写时,数据将直接进入主存储器,而PCI设备进行DMA读所读取的数据将直接从主存储器获得。......
2023-10-20

PCI设备向“可Cache的存储器空间”进行读操作的过程相对简单。Snoop Agent在Snoop Phase进行总线监听,并通过HIT#和HITM#信号将监听结果通知给Response Agent。下面以图3-7所示的SMP处理器系统为例,说明PCI设备对“可Cache的存储器空间”进行DMA写的实现过程。图3-7 PCI设备向可Cache的存储器空间进行写操作在图3-7所示的处理器系统中,存在4个CPU,这4个CPU通过一条FSB连接在一起,CPU之间使用MESI协议进行Cache一致性处理,而HOST主桥和存储器控制器与FSB直接相连。......
2023-10-20
有的比例尺做成三棱柱状,称为三棱尺。三棱尺上刻有6种刻度,通常分别表示为1∶100、1∶200、1∶300、1∶400、1∶500、1∶600等6种比例。现以比例直尺为例,说明它的用法。图2.7比例尺及其用法①用比例尺量取图上线段长度。例如,在图2.7中,AB线段的比例如果改为1∶2,由于比例尺1∶200刻度的单位长度比1∶2缩小了100倍,则AB线段的长度应读为,同样,比例改为1∶2 000,则应读为15.2×10=152m。上述量读方法可归结为表2.1。......
2023-10-13

项目八机械零件图样的识读与绘制项目要术机械零件图样简称零件图,是设计部门提交给生产部门,用以指导生产机器零件的重要技术文件之一。图8-1电机支架轴测图零件图的内容:1.一组视图。表面结构的各项要求在图样上的表示法在GB/T 131—2006中均有规定。其中轮廓参数是我国机械图样中目前最常用的评定参数。......
2024-10-25

图12-10 PCIe总线TLP格式由上图所示,一个PCIe设备发送TLP报文时,在经过数据链路层和物理层时,需要加上若干前缀和后缀。TLP在传送过程中,需要通过PCIe总线的事务层、数据链路层和物理层,因此必须考虑这些协议所带来的开销。在这两种情况之下,事务层的开销不同。由公式12-11,可以计算出与Max_Payload_Size参数对应的Payload_Ratio,并由此推算存储器写TLP在事务层上的开销。本章以这种方式为例分析存储器读TLP在事务层中的开销。......
2023-10-20
当TLP的TH位为1时,表示在当前TLP中包含Processing Hint字段,PH字段由PCIe V2.1总线规范引入。Processing Hint字段的产生与智能设备的大量涌现密切相关。有些智能设备,如在显卡中使用的GPU和GP-GPU的处理能力甚至超过多数通用处理器。该TLP Prefix也被称为TPH TLP Prefix,其格式如图6-15所示。TPH Requester Capability结构使用ST Mode Sele ct字段定义了ST字段的三种使用模式。......
2023-10-20
相关推荐