【摘要】:VC不同的TLP间没有序的要求,在PCIe总线中,“序”是指VC相同的TLP之间的传送顺序,其关系如表11-5所示。表11-5 PCIe总线的序各个表项的含义如下。如在第11.1.1节描述的生产/消费者模型中,生产者首先将数据写入数据缓冲,然后将Flag位置1。B2 b对应TLP的IDO位为1的情况。
VC不同的TLP间没有序的要求,在PCIe总线中,“序”是指VC相同的TLP之间的传送顺序,其关系如表11-5所示。
表11-5 PCIe总线的序
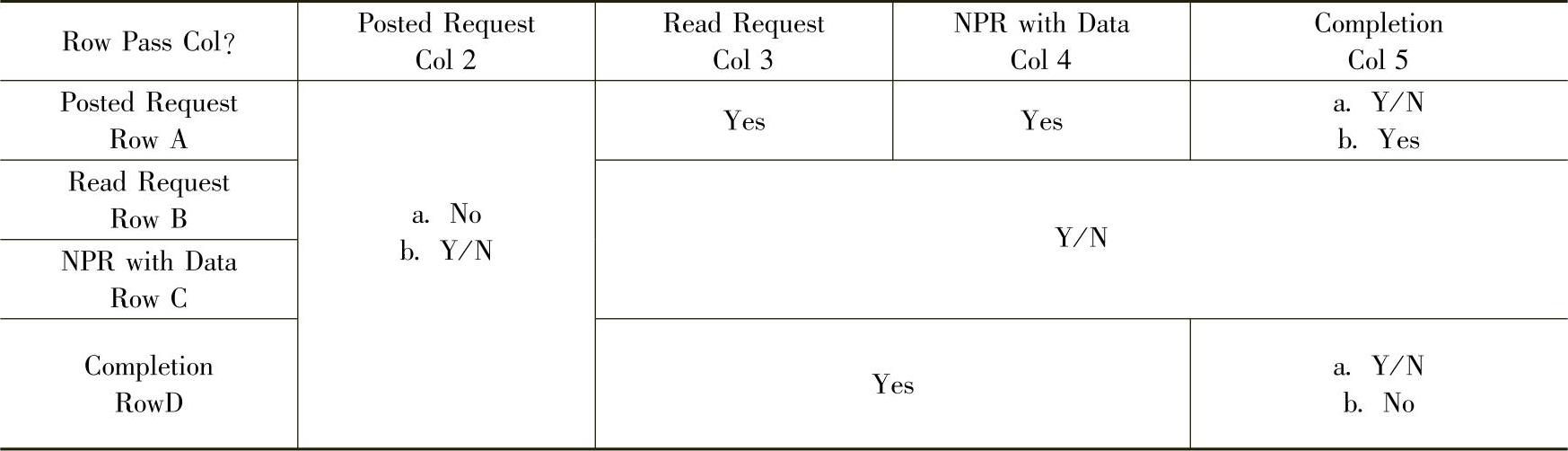
各个表项的含义如下。
●Posted Request由存储器写请求TLP或者Message使用。
●Read Request由I/O、配置和存储器读请求使用。
●NPR(Non-Posted Request)with Data由I/O、配置写和原子操作使用。
●a.表示TLP的RO位为0,即不使能Relaxed Order的情况。
●b.表示TLP的RO位为1或者IDO位为1,即使能Relaxed Ordering或者使能ID-Based Ordering的情况。不同的规则使用a,b子规则略有差异。
●Yes表示Row中的TLP必须能够穿越Col中的TLP。
●Y/N表示Row中的TLP和Col中的TLP没有序的关系。
●No表示Row中的TLP一定不能穿越Col中的TLP。
下文出现的XY a/b中,X与行对应,其值为A~D,Y与列对应,其值为2~5。如A2a表示“Posted Request”在RO位为0的情况下是否能够超越“Posted Request”。
通过表11-5与表11-4的比较,可以发现在RO位为0时(即不使用Relax Orderin g),PCIe总线的序与PCI的序基本兼容。但是因为在一个TLP中有时RO位和IDO位不为0,因此PCIe总线的序需要根据a和b两种情况分别进行讨论。
1.A2
A2需要分为两种情况讨论,其中a对应TLP的RO和IDO位都为0情况,而b对应TLP的RO或者IDO位为1的情况。
A2 a的值为No,表示Posted Request报文不能超越之前的Posted Request报文,这与PCI总线中PMW不能超越之前的PMW要求相同。PCI总线的PMW与PCIe的Posted Request报文基本一致,存储器写和Message使用这类报文。
A2 b的值为Y/N,该规则需要分为两种情况进行讨论,RO位为1或者IDO位为1。当RO位为1时,该Posted Request报文可以超越之前的Posted Request报文。在设计中应用该规则是十分危险的,该规则也意味着“写”可以超越“写”。
如在第11.1.1节描述的生产/消费者模型中,生产者首先将数据写入数据缓冲,然后将Flag位置1。如果“将Flag位置1”的写操作可以超越“写入数据缓冲”的写操作,那么消费者可能会从无效的数据缓冲中读取数据,从而出现错误。
在Switch和支持Peer-to-Peer传送的RC中,设置了一个寄存器位“No RO-enabled PR-PR Passing”[78],当该位为1时,当TLP通过这些Switch和RC时,Posted Request报文不能超越之前的Posted Request报文,即便这些TLP的RO位为1。
当IDO位为1时,该Posted Request报文可以超越之前的Posted Request报文。使用该规则的前提是,这两个Posted Request报文使用的Requester ID号不同,即这两个Posted Re-quest报文是由不同的PCIe设备发出的,有关IDO序的详细说明见第11.4.2节。
2.A3和A4
A3和A4的值为Yes,表示Posted Request报文可以超越之前的Non-Posted读和写请求。该规则与PCI总线的PMW可以超越DRR和DWR兼容,其主要目的是避免死锁。详见PCI总线序的规则5。
3.A5
A5需要分为两种情况讨论,a适用于PCIe总线中的RC和Switch;而b适用于PCIe桥。
A5 a的值为Y/N。在PCIe总线中,Posted Request报文可以超越之前的完成报文也可以不超越,在这两种情况下,都不会造成死锁。该规则与PCI总线中PMW必须超越DRC和DWC不同(PCI总线中的规则7),因为在PCI体系结构中会出现不同版本的PCI桥,而在PCIe体系结构中不会出现这种情况。
A5 b的值为Yes。表示在PCIe桥中,PCIe总线向PCI总线的方向传递报文时,Posted Request报文必须可以超越完成报文,以避免死锁。PCIe桥内部由多个虚拟PCI桥组成,参见图4-13,因此PCIe总线中的A5 b与PCI总线中的规则7兼容。
4.B2,C2
B2需要分为两种情况讨论,其中a对应TLP的IDO位为0情况,而b对应TLP的IDO位为1的情况。
B2 a的值为No,表示Read Request报文不能超越之前的Posted Request报文,这与PCI总线中DRR不能超越之前的PMW要求相同。PCI总线的DRR与PCIe总线的Read Request报文基本一致,存储器、I/O和配置读使用这类报文。
B2 b对应TLP的IDO位为1的情况。当IDO位为1时,该Read Request报文可以超越之前的Posted Request报文,否则不能超越。使用该规则的前提是,Read Reques报文和Pos-ted Request报文使用的Requester ID号不同。
C2也需要分为两种情况讨论,其中a对应TLP的IDO位为0情况,而b对应TLP的IDO位为1的情况。其实现机制与B2类似,本节对此不做进一步说明。(www.chuimin.cn)
5.B3,B4,C3,C4
在PCIe总线中,Non-Posted Request报文可以超越之前的Non-Posted Request报文,也可以不进行这种超越。该规则从PCI总线中继承而来,而在PCI总线中DRR/DWR可以超越之前的DRR/DWR。PCIe设备在实现中,需要与该规则兼容。
但是在PCIe总线中,存储器读操作使用Split方式进行传送,因此该规则的引入为PCIe设备的设计带来了不小的麻烦。当一个EP进行DMA读操作时,需要首先向RC发送存储器读请求,如R1~R4,而RC收到这些读请求时,将回送读完成TLP,如C1~C4。为简便起见,我们认为每一个存储器读请求的大小为64B,而读完成的大小也为64B,而且不考虑对界的问题,这样EP发送的存储器读请求将与RC的读完成一一对应,我们假设R1对应C1,R2对应C2,并以此类推R4对应C4。
EP首先按照R1~R4的顺序发送这些存储器读请求。但是R1~R4在通过Switch和RC之后可能出现乱序,如果Non-Posted Request报文可以超越之前的Non-Posted Request报文,RC最终收到的存储器读请求可能是乱序的,如R2,R4,R3和R1,因此RC发送给EP的读完成报文可能为C2,C4,C3和C1,这个顺序与EP发向RC的存储器读请求的顺序并不相同。因此EP必须处理这种乱序,这为EP的设计带来了不小的困难。
6.B5,C5
在PCIe总线中,Non-Posted Request报文与之前的完成报文没有序的要求。该规则从PCI总线中继承而来,在PCI总线中DRR/DWR可以超越之前的DRC/DWC,也可以不超越。这些报文的传递不会影响生产/消费者模型的正常运行。
7.D2
D2需要分为两种情况进行讨论,分别是D2 a和D2 b。
其中D2 a为No,表示在PCIe总线中,CplD报文不能超越Posted Request报文,该规则与PCI总线中的规则4兼容。这也是保证生产/消费者模型正常运行的必要条件。
而D2 b为Y/N。如果TLP的RO位为1时,该CplD报文可以超越Posted Request报文。设计者需要慎重使用该规则,因为该规则的应用有可能破坏生产/消费者模型的正常运转。只有传递与生产/消费者模型无关的报文时,才能应用该规则。
此外如果TLP的IDO位为1时,该CplD报文可以超越之前的Posted Request报文,否则不能超越。使用该规则的前提是,CplD报文和Posted Request报文使用的Requester ID号不同。值得注意的是,Cpl报文由I/O或者配置写完成报文使用,该报文中不含有数据,仅包含完成信息。该报文的使用方法与PCI总线的DWC类似。该报文与Posted Request报文没有序的要求,该规则与PCI总线的规则4兼容。
8.D3,D4
在PCIe总线中,完成报文可以超越之前的Non-Posted Request报文。该规则从PCI总线中继承而来,与规则6对应。该规则的引入主要为了防止死锁。
9.D5
如果完成报文与之前的完成报文的Transaction ID不同时,该报文可以超越之前的完成报文;如果相同,不能进行这样的超越。
当一个PCIe设备向目标设备发送存储器读请求时,目标设备可能会使用一个或者多个存储器读完成报文将数据回送。如果使用多个存储器读完成报文时,这些存储器完成报文按“地址升序”顺序先后到达源设备。
如果设备A需要从设备B读取256B[79]的数据,其访问的地址为0x1000-0000~0x1000-00FF时,设备A可以向设备B发送一个存储器读请求TLP,而设备B将以64B为单位向设备A发送存储器读完成TLP,这些完成报文必须以C1~C4的顺序到达设备A,C1~C4存储器读完成TLP对应的数据区域如下。
●C1与0x1000-0000~0x1000-003F对应。
●C2与0x1000-0040~0x1000-007F对应。
●C3与0x1000-0080~0x1000-00BF对应。
●C4与0x1000-00C0~0x1000-00FF对应。
如果设备A需要从设备B读取512B的数据,访问的地址为0x1000-0000~0x1000-01FF时,这段数据区域大于大于设备A的Max_Read_Request_Size参数,因此设备A需要向设备B发出两个存储器读请求,这两个存储器读请求使用两个不同的Tag字段进行区分,分别为RT0和RT1。假设RT0的Tag字段为0,其请求的数据区域为0x1000-0000~0x1000-00FF;而RT1的Tag字段为1,其请求的数据区域为0x1000-0100~0x1000-01FF。
假设设备A首先发送RT0,然后再发送RT1。但是设备B仍然可能首先收到RT1,然后再收到RT0,因为PCIe总线允许存储器读请求超越存储器读请求。设备B收到这些存储器读请求后,向设备A发送存储器读完成TLP(以64B为单位),分别为C1T0~C4T0和C1T1~C4T1。
其中C1T0~C4T0使用的Tag字段为0,而C1T1~C4T1使用的Tag字段为1,分别与RT0和RT1对应,这也意味着这两组存储器读完成使用的Transaction ID不同,因此可以彼此超越,这两组存储器读完成TLP对应的数据区域如下。
●C1T0与0x1000-0000~0x1000-003F对应;C2T0与0x1000-0040~0x1000-007F对应;C3T0与0x1000-0080~0x1000-00BF对应;C4T0与0x1000-00C0~0x1000-00FF数据区域对应。
●C1T1与0x1000-0100~0x1000-013F对应;C2T1与0x1000-0140~0x1000-017F对应;C3T1与0x1000-0180~0x1000-01BF对应;C4T1与0x1000-01C0~0x1000-01FF数据区域对应。
此时设备A收到的存储器读完成,有多种可能,如表11-6所示。
表11-6 设备A收到的存储器读完成序列
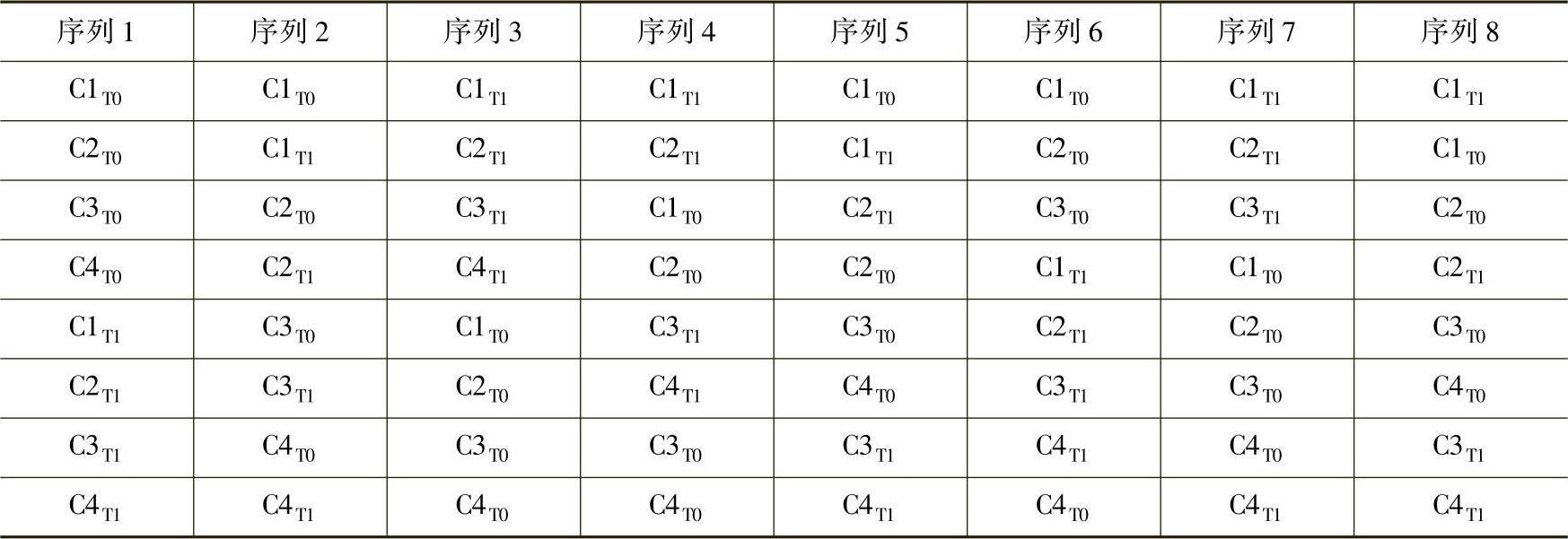
上表仅列出了设备A可能从设备B中收到的存储器读完成序列。由此可见对于Tag字段不同的存储器完成报文,在到达设备A时顺序并不确定。但是对于Tag字段相同的存储器读完成TLP,这些存储器完成报文是严格按照地址“升序”的顺序到达设备A。PCIe总线的这种乱序为PCIe设备的设计带来了不小的麻烦,设计者必须认真地处理这些乱序可能。






相关推荐