【摘要】:综上所述,使用N23算法进行数据报文的传递时,只要N2和N3参数设置合理,将不会发生节点的Overrun和Underrun的情况。采用N23算法可以有效避免这种因为Credit报文传递不及时而引发的Underrun。
N23算法是流量控制中常用的算法,使用该算法的优点是Current节点的缓存中不包含N1,从而降低了节点的缓存容量。该算法基于N123算法,区别在于使用该算法时Crd_Bal参数的计算。基于该算法的实现方式如图9-7所示。
N23算法的使用规则如下。
●当系统初始化时,Crd_Bal参数为N2+N3-E,E为在时间段RTT中,Upstream节点向Current节点发送的报文数,其值等于BVCR×RTT/Packet_Size。而Upstream节点每发送一个报文,Crd_Bal参数的值将减1。当Crd_Bal参数等于0时,Upstream节点停止发送报文,直到重新获得Current节点的Credit报文,更新Crd_Bal参数后,才能继续发送。
●使用N23算法时,Crd_Bal参数与Current节点发出的Credit并不相等,而是等于Credit-E。
●Current节点至少需要向Downstream节点发送N2个报文后,才能向Upstream节点发送Credit报文,与N123算法一致。
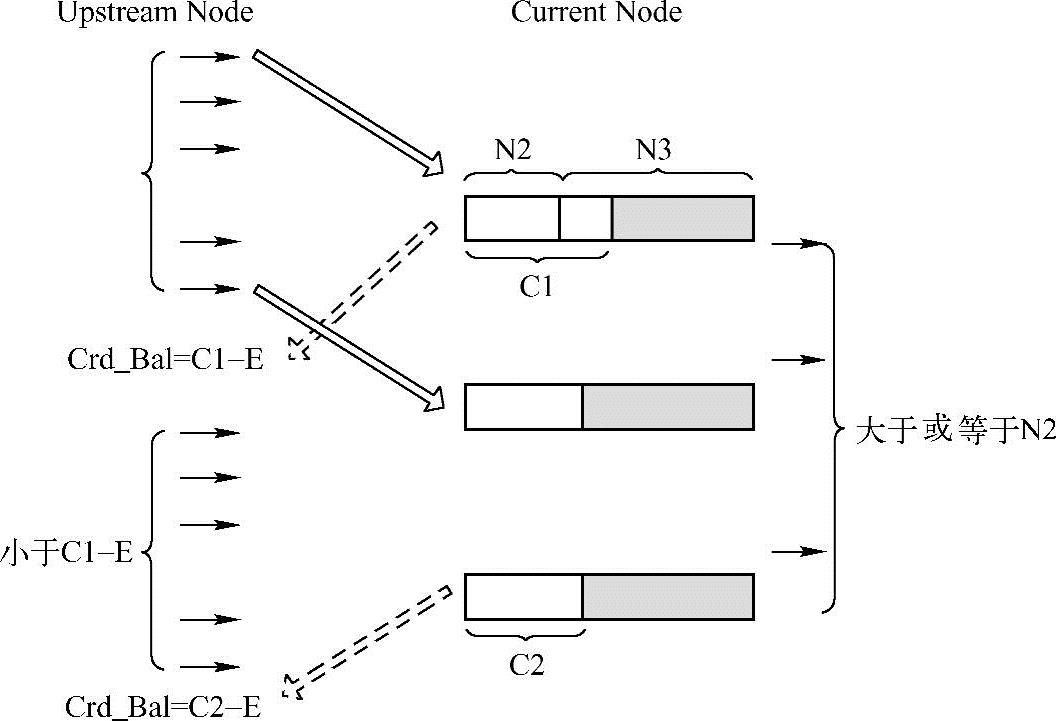
图9-7 基于N23算法的流量控制
通过以上介绍,可以发现之所以采用N23算法,不需要设置N1,是因为Upstream节点使用的Crd_Bal参数与N123算法相比少E个包,所以N23算法虽然没有使用N1缓冲,也不会导致在传送过程中出现Overrun,因为采用N23算法,将N1隐含在E中。同时因为N3的存在,采用N23算法也不会导致在传送过程中出现Underrun。
综上所述,使用N23算法进行数据报文的传递时,只要N2和N3参数设置合理,将不会发生节点的Overrun和Underrun的情况。但是还需要继续讨论Current节点发送Credit报文时会不会引发Overrun和Underrun。
首先Current节点发送Credit报文不会引发Upstream节点的Overrun,因为Upstream节点每次接收到新的Credit报文都会把Crd_Bal参数更新,不可能因为Credit报文过多而无法处理。但是Current节点发送过多的Credit报文将严重影响物理链路的有效利用率,在流量机制的实现中,需要合理设置发送Credit报文的频率。
而Current节点向Upstream节点传递Credit报文延时过大时,可能会引发Current节点的Underrun。在这种情况下,Upstream节点虽然有很多报文等待发送,但是由于Crd_Bal参数为0,不能发送这些报文。
因此造成在Current节点的数据缓冲中,没有数据报文需要发向Downstream节点,尽管此时在Current节点中还有足够的缓存可以接收数据报文。在流量控制机制的设计中,需要考虑Credit报文的传送延时,合理设置Current节点中的缓冲,以保证Upstream节点在获得新的Credit之前,Current节点的缓冲中具有一定的报文数,以避免Underrun。
采用N23算法可以有效避免这种因为Credit报文传递不及时而引发的Underrun(N123算法与N23算法都使用了N3缓冲避免Current节点的Underrun)。我们首先基于N23算法做出以下假设以简化数学模型。(www.chuimin.cn)
(1)N3=BVCR×RTT/Packet_Size。设置N3缓存的主要目的是保证Current节点不会出现Underrun。而BVCR×RTT/Packet_Size是N3缓存的最小值。
(2)Upstream、Current和Downstream间VC的通信带宽为BVCR,其值为一个常数。
(3)Downstream节点始终有足够的缓冲接收报文。Current节点可以通畅地将数据报文转发到Downstream节点。
Upstream和Current节点间的数据交换是基于“得到Credit,然后发送数据”这样的循环。假定在一个发送循环的起始点中,Upstream节点的Crd_Bal参数为N2,即Upstream节点刚收到的Credit为N2+N3,而采用N23算法时,Crd_Bal=Credit-E=(N2+N3)-E=N2。
我们定格Upstream节点刚刚收到Current节点Credit报文,更新Crd_Bal参数完毕这个场景,其时间戳为T2,而Current节点发送这个Credit报文的时间戳为T1。假设从T1~T2这段时间内,Current节点收到z2个报文(Current节点向Upstream节点发送Credit报文的过程中,仍然在持续地接收报文)。T1~T3的示意如图9-8所示。

图9-8 T1~T3的示意图
由于各节点的带宽都为BVCR,所以Current节点每收到一个报文,都会发送到Down-stream节点,因此此时Current节点的可用缓存始终保持为N2+N3。Current节点向Upstream节点发送的Credit报文始终为N2+N3,而Upstream节点收到这个Credit后,其Crd_Bal参数将被置为N2。
Upstream节点收到Credit报文后,开始向Current节点发送N2个报文,Upstream节点每发送一个报文,Current节点将收到一个报文(假设此时从Upstream节点到Current节点的链路之间已经堆积了z2个报文,此时物理链路已经充满数据报文)。
假设Upstream节点向Current节点发送完毕N2-z2个报文(数据报文离开发送端口的时间戳为T3)。那么从T3~T1这段时间里,Current节点将收到N2个报文,同时Current节点也将向Downstream节点转发完毕N2个报文,此时(T3时间戳)Current节点将向Up-stream节点发送Credit报文(数值为N2+N3)。
而Upstream节点处于T3这个时刻时,还能向Current节点发送z2个报文,因为之前已经发送了N2-z2个报文,此时Crd_Bal参数为z2。等到Upstream节点将z2个报文发送完毕,来自Current节点的Credit报文恰好到达,因为Upstream节点将z2个报文发送完毕的时间刚好等于Current节点向Upstream节点发送Credit报文的时间。通过以上计算,可以发现采用N23算法不会因为Credit报文的传送时间而导致Current节点的Underrun。
此外采用N23算法时还需要处理错误报文,N23算法规定当一个节点收到一个错误数据报文时,将丢弃这个报文,此时这个被丢弃的报文将不占用接收节点的缓存,但是发送节点的Crd_Bal参数仍然需要考虑这个报文。






相关推荐