TLP的AT字段与ATS机制直接相关。该报文由PCIe设备通过存储器读请求TLP发出,其目的地为TA。如果TLP中的Address字段没有经过ATC进行地址转换,而且处理器系统支持虚拟化技术,该地址为仍然对应GPA地址在PCI总线域中的映像,此时该TLP使用的AT字段为0b00。由以上描述可以发现,PCIe设备无论是否使用ATC机制,在TLP中存放的Address字段仍然保存的是PCI总线地址。......
2023-10-20
Attr字段由3位组成,其中第2位表示该TLP是否支持PCIe总线的ID-based Ordering;第1位表示是否支持Relaxed Ordering;而第0位表示该TLP在经过RC到达存储器时,是否需要进行Cache共享一致性处理。Attr字段如图6-3所示。
一个TLP可以同时支持ID-based Ordering和Relaxed Orde-ring两种位序。Relaxed Ordering最早在PCI-X总线规范中提出,用来提高PCI-X总线的数据传送效率;而ID-based Orde-ring由PCIe V2.1总线规范提出。TLP支持的序如表6-3所示。
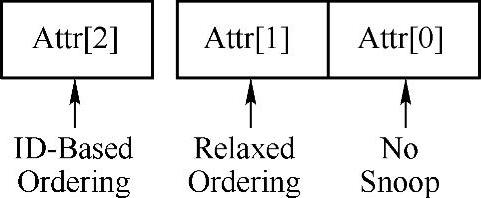
图6-3 Attr字段格式
表6-3 TLP支持的序

当使用标准的强序模型时,在数据的整个传送路径中,PCIe设备在处理相同类型的TLP时,如PCIe设备发送两个存储器写TLP时,后面的存储器写TLP必须等待前一个存储器写TLP完成后才能被处理,即便当前报文在传送过程中被阻塞,后一个报文也必须等待。
如果使用Relaxed Ordering模型,后一个存储器写TLP可以穿越前一个存储器写TLP,提前执行,从而提高了PCIe总线的利用率。有时一个PCIe设备发出的TLP,其目的地址并不相同,可能先进入发送队列的TLP,在某种情况下无法发送,但这并不影响后续TLP的发送,因为这两个TLP的目的地址并不相同,发送条件也并不相同。(www.chuimin.cn)
值得注意的是,在使用PCI总线强序模型时,不同种类的TLP间也可以乱序通过同一条PCIe链路,比如存储器写TLP可以超越存储器读请求TLP提前进行。而PCIe总线支持Relaxed Ordering模型之后,在TLP的传递过程中出现乱序种类更多,但是这些乱序仍然是有条件限制的。在PCIe总线规范中为了避免死锁,还规定了不同报文的传送数据规则,即Ordering Rules。有关PCIe总线序的详细说明见第11章。
PCIe V2.1总线规范引入了一种新的“序”模型,即IDO(ID-Based Ordering)模型,IDO模型与数据传送的数据流相关,是PCIe V2.1规范引入的序模型。有关PCIe总线的Re-laxed Orderin g和IDO模型的详细说明见第11.4.2节。
Attr字段的第0位是“No Snoop Attribute”位。当该位为0时表示当前TLP所传送的数据在通过FSB时,需要与Cache保持一致,这种一致性由FSB通过总线监听自动完成而不需要软件干预;如果为1,表示FSB并不会将TLP中的数据与Cache进行一致,在这种情况下,进行数据传送时,必须使用软件保证Cache的一致性。
在PCI总线中没有与这个“No Snoop Attribute”位对应的概念,因此一个PCI设备对存储器进行DMA操作时会进行Cache一致性操作[19]。这种“自动的”Cache一致性行为在某些特殊情况下并不能带来更高的效率。
当一个PCIe设备对存储器进行DMA读操作时,如果传送的数据非常大,比如512MB,Cache的一致性操作不但不会提高DMA写的效率,反而会降低。因为这个DMA读访问的数据在绝大多数情况下,并不会在Cache中命中,但是FSB依然需要使用Snoop Phase进行总线监听。而处理器在进行Cache一致性操作时仍然需要占用一定的时钟周期,即在Snoop Phase中占用的时钟周期,Snoop Phase是FSB总线事务的一个阶段,如图3-6所示。
对于这类情况,一个较好的做法是,首先使用软件指令保证Cache与主存储器的一致性,并置“No Snoop Attribute”位为1[20],然后再进行DMA读操作。同理使用这种方法对一段较大的数据区域进行DMA写时,也可以提高效率。
除此之外,当PCIe设备访问的存储器,不是“可Cache空间”时,也可以通过设置“No Snoop Attribute”位,避免FSB的Cache共享一致性操作,从而提高FSB的效率。“No Snoop Attribute”位是PCIe总线针对PCI总线的不足作出的重要改动。
有关PCI Express体系结构导读的文章

TLP的AT字段与ATS机制直接相关。该报文由PCIe设备通过存储器读请求TLP发出,其目的地为TA。如果TLP中的Address字段没有经过ATC进行地址转换,而且处理器系统支持虚拟化技术,该地址为仍然对应GPA地址在PCI总线域中的映像,此时该TLP使用的AT字段为0b00。由以上描述可以发现,PCIe设备无论是否使用ATC机制,在TLP中存放的Address字段仍然保存的是PCI总线地址。......
2023-10-20

在一段程序中,存在大量的分支预测指令,因而在某种程度上增加了指令Fetch的难度。但是分支预测单元并不会每次都能正确判断分支指令的执行路径,这为指令Fetch制造了不小的麻烦,在这个背景下许多分支预测策略应运而生。在PowerPC处理器中,条件转移指令“bc”表示Taken;而“bc-”表示Not Taken。BTB的功能相当于存放转移指令的Cache,其状态机转换也与Cache类似。转移指令B执行完毕后,将实际执行结果Rc更新到BHR寄存器中,并同时更新PHT中对应的Entry。......
2023-10-20

如图8-6所示,Detect状态由Detect.Quiet、Detect.Active两个子状态组成。在正常情况下,PCIe链路将从Detect状态迁移到Polling状态。而在Detect状态中,PCIe设备的发送逻辑TX将直接进入到“Electrical Idle”状态,并不会使用Idle序列通知对端设备的接收逻辑RX。当PCIe设备处于Detect.Quiet状态超过12ms之后,或者检测到PCIe链路上的任何一个Lane退出“Electrical Idle”状态时,PCIe设备将进入Detect.Active状态。......
2023-10-20

而PCI总线的突发传送仍然存在缺陷。为此PCI-X总线使用基于数据块的突发传送方式,发送端以ADB为单位,将数据发送给接收端,一次突发读写为一个以上的ADB。采用这种方式,接收端可以事先预知是否有足够的接收缓冲,接收来自发送端的数据,从而可以及时断连当前总线周期,以节约PCI-X总线的带宽。因此在PC领域和嵌入式领域很少有基于PCI-X总线的设备,PCI-X设备仅在一些高端服务器上出现。因此本节不对PCI-X总线做进一步描述。......
2023-10-20

MSI Capability结构共有四种组成方式,分别是32和64位的Message结构,32位和64位带中断Masking的结构。MSI Capability寄存器的结构如图10-1所示。图10-1 MSI Capability结构●Capability ID字段记载MSI Capability结构的ID号,其值为0x05。表10-1 MSI Cabalibities结构的Message Control字段[67] 此时PCI设备配置空间Command寄存器的“Interrupt Disable”位为1。当MSI En able位有效时,该字段存放MSI报文使用的数据。该字段需要与Mask Bits字段联合使用。......
2023-10-20

当TLP的TH位为1时,表示在当前TLP中包含Processing Hint字段,PH字段由PCIe V2.1总线规范引入。Processing Hint字段的产生与智能设备的大量涌现密切相关。有些智能设备,如在显卡中使用的GPU和GP-GPU的处理能力甚至超过多数通用处理器。该TLP Prefix也被称为TPH TLP Prefix,其格式如图6-15所示。TPH Requester Capability结构使用ST Mode Sele ct字段定义了ST字段的三种使用模式。......
2023-10-20

使用N123算法时,需要设置N1缓冲处理这些因为网络延时产生的报文。希望读者认真理解N1缓冲在N123算法中的意义。N123+算法基于N123算法,但是发送Credit报文的方式略有不同。N123算法要求Cur-rent节点每转发N2个报文后,才能给Upstream节点发送一个Credit报文;而N123+算法除了要求同样的规则之外,还要求Current节点在一个时间段RTT中至少发送一个Credit报文,即发送上一个Credit报文之后,即便Current节点没有向Downstream转发了N2报文,在一个时间段RTT中也至少要向Upstream节点发送一次Credit报文。......
2023-10-20
在PCIe总线中存在两种仲裁机制,分别是基于VC和基于端口的仲裁机制。端口仲裁机制主要针对RC和Switch,当多个Ingress端口需要向同一个Egress端口发送数据报文时需要进行端口仲裁。当RC的端口1和端口3同时访问Endpoint C时,RC的端口2需要进行端口仲裁,决定来自RC哪个端口的数据可以率先通过。PCIe总线规定,系统设计者可以使用以下三种方式进行端口仲裁。......
2023-10-20
相关推荐