【摘要】:在一段程序中,存在大量的分支预测指令,因而在某种程度上增加了指令Fetch的难度。但是分支预测单元并不会每次都能正确判断分支指令的执行路径,这为指令Fetch制造了不小的麻烦,在这个背景下许多分支预测策略应运而生。在PowerPC处理器中,条件转移指令“bc”表示Taken;而“bc-”表示Not Taken。BTB的功能相当于存放转移指令的Cache,其状态机转换也与Cache类似。转移指令B执行完毕后,将实际执行结果Rc更新到BHR寄存器中,并同时更新PHT中对应的Entry。
指令预读是CPU指令流水的一个阶段。
在一段程序中,存在大量的分支预测指令,因而在某种程度上增加了指令Fetch的难度。因此如何判断程序的执行路径是指令流水首先需要解决的问题。
在CPU中通常设置了分支预测单元(Branch Predictor),在分支指令执行之前,分支预测单元需要预判分支指令的执行路径,从而进行指令Fetch。但是分支预测单元并不会每次都能正确判断分支指令的执行路径,这为指令Fetch制造了不小的麻烦,在这个背景下许多分支预测策略应运而生。
这些分支预测策略主要分为静态预测和动态预测两种方法。静态预测方法的主要实现原理是利用Profiling工具,静态分析程序的架构,并为编译器提供一些反馈信息,从而对程序的分支指令进行优化。如在PowerPC处理器的转移指令中存在一个“at”字段,该字段可以向CPU提供该转移指令是否Taken[43]的静态信息。在PowerPC处理器中,条件转移指令“bc”表示Taken;而“bc-”表示Not Taken。
CPU的分支预测单元在分析转移指令时可以预先得知该指令的转移结果。目前在多数CPU中提供了动态预测机制,而且动态预测的结果较为准确。因此在实现中,许多PowerPC内核并不支持静态预测机制,如E500内核。
CPU使用的动态预测机制是本节研究的重点。而在不同的处理器中,分支预测单元使用的动态预测算法并不相同。在一些功能较弱的处理器,如8 b/16 b微控制器中,分支指令的动态预测机制较为简单。在这些处理器中,分支预测单元常使用以下几种方法动态预测分支指令的执行。
(1)分支预测单元每一次都将转移指令预测为Taken,采用这种方法无疑非常简单,而且命中率在50%以上,因为无条件转移指令都是Taken,当然使用这种方法的缺点也是显而易见的。
(2)分支预测单元将向上跳转的指令预测为Taken,而将向下跳转的指令预测为Not Taken。分支预测单元使用的这种预测方式与多数程序的执行风格类似,但是这种实现方式并不理想。
(3)一条转移指令被预测为Taken,而之后这条转移指令的预测值与上一次转移指令的执行结果相同。
当采用以上几种方法时,分支预测单元的硬件实现代价较低,但是使用这些算法时,预测成功的概率较低。因此在高性能处理器中,如PowerPC和x86处理器并不会采用以上这3种方法实现分支预测单元。
目前在高性能处理器中,常使用BTB(Branch Target Buffer)管理分支预测指令。在BTB中含有多个Entry,这些Entry由转移指令的地址低位进行索引,而这个Entry的Tag字段存放转移指令的地址高位。BTB的功能相当于存放转移指令的Cache,其状态机转换也与Cache类似。当分支预测单元第一次分析一条分支指令时,将在BTB中为该指令分配一个Entry,同时也可能会淘汰BTB中的Entry。目前多数处理器使用LRU(Least recently used)算法淘汰BTB中的Entry。
在BTB的每个Entry中存在一个Saturating Counter。该计数器也被称为Bimodal Predic-tor,由两位组成,可以表示4种状态,为0b11时为“Strongly Taken”;为0b10时为“Weak-ly Taken”;为0b01时为“Weakly not Taken”;为0b00时为“Strongly not Taken”。
当CPU第一次预测一条转移指令的执行时,其结果为Strongly Taken,此时CPU将在BTB中为该指令申请一个Entry,并置该Entry的Saturating Counter为0b11。此后该指令将按照Saturating Counter的值,预测执行,如果预测结果与实际执行结果不同时,将Saturating Counter的值减1,直到其值为0b00;如果相同时,将Saturating Counter的值加1,直到其值为0b11。目前Power E500内核和Pentium处理器使用这种算法进行分支预测。
使用Saturating Counter方法在处理转移指令的执行结果为1111011111或者0000001000时的效果较好,即执行结果大多数为0或者1时的预测结果较好。然而如果一条转移指令的执行结果具有某种规律,如为010101010101或者001001001001时,使用Saturating Counter并不会取得理想的预测效果。(www.chuimin.cn)
在程序的执行过程中,一条转移指令在执行过程中出现这样有规律的结果较为常见,因为程序就是按照某种规则编写的,按照某种规则完成指定的任务。为此Two-Level分支预测方法应运而生。
Two-Level分支预测方法使用了两种数据结构,一种是BHR(Branch History Register);而另一种是PHT(Pattern History Table)。其中BHR由k位组成,用来记录每一条转移指令的历史状态,而PHT表含有2k个Entry,每个Entry由两位Saturating Counter组成。BHR和PHT的关系如图3-10所示。
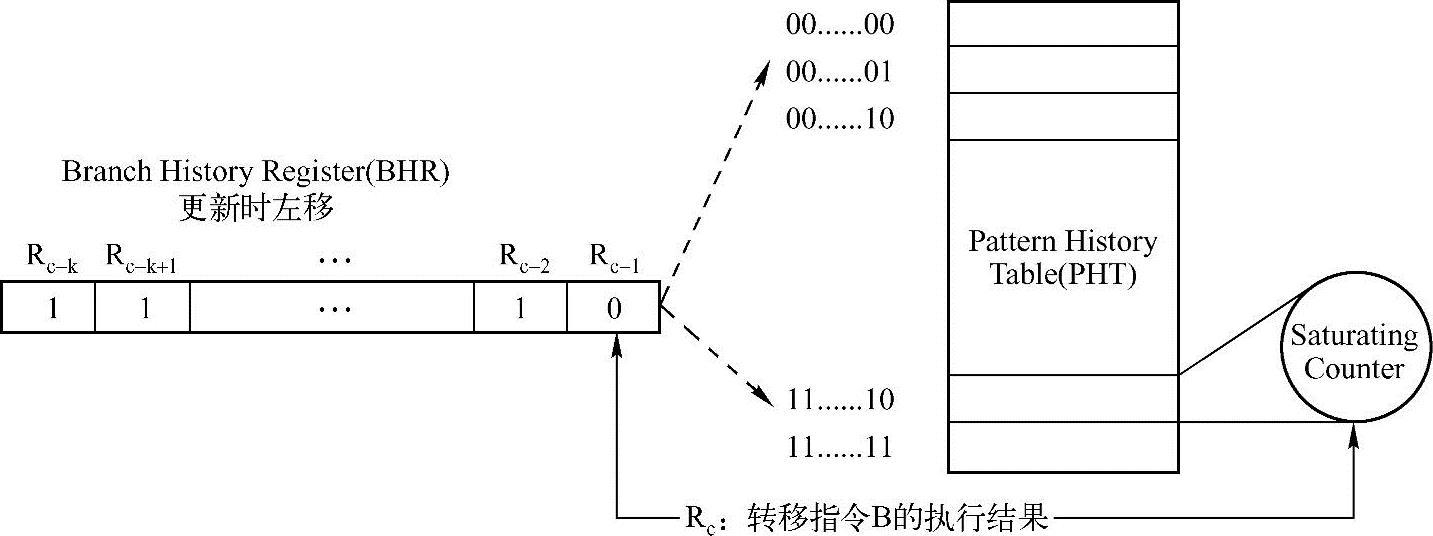
图3-10 BHR和PHT之间的关系
假设分支预测单元在使用Two-Level分支预测方法时,设置了一个PBHT表(Per-ad-dress Branch History Table)存放不同指令所对应的BHR。在PBHT表中所有BHR的初始值为全1,而在PHT表中所有Entry的初始值值为0b11。BHR在PBHT表中的使用方法与替换机制与Cache类似。
当分支预测单元分析预测转移指令B的执行时,将首先从PBHT中获得与转移指令B对应的BHR,此时BHR为全1,因此CPU将从PHT的第11…11个Entry中获得预测结果0b11,即Strongly Taken。转移指令B执行完毕后,将实际执行结果Rc更新到BHR寄存器中,并同时更新PHT中对应的Entry。
当CPU再次预测转移指令B的执行时,仍将根据BHR索引PHT表,并从对应Entry中获得预测结果。而当指令B再次执行完毕后,将继续更新BHR和PHT表中对应的Entry。当转移指令的执行结果具有某种规律(Pattern)时,使用这种方法可以有效提高预测精度。如果转移指令B的实际执行结果为001001001…001,而且k等于4时,CPU将以0010-0100-1001这样的循环访问BHR,因此CPU将分别从PHT表中的第0010、0100和1001个Entry中获得准确的预测结果。
由以上描述可以发现,Two-Level分支预测法具有学习功能,并可以根据转移指令的历史记录产生的模式,在PHT表中查找预测结果。该算法由T.Y.Yeh与Y.N.Patt在1991年提出,并在高性能处理器中得到了大规模应用。
Two-Level分支预测法具有许多变种。目前x86处理器主要使用“Local Branch Predic-tion”和“Global Branch Prediction”两种算法。
在“Local Branch Prediction”算法中,每一个BHR使用不同的PHT表,Pentium Ⅱ和Pentium Ⅲ处理器使用这种算法。该算法的主要问题是当PBHT表的Entry数目增加时,PHT表将以指数速度增长,而且不能利用其他转移指令的历史信息进行分支预测。而在“Global Branch Prediction”算法中,所有BHR共享PHT表,Pentium M、Pentium Core和Core 2处理器使用这种算法。
在高性能处理器中,分支预测单元对一些特殊的分支指令如“Loop”和“Indirect跳转指令”设置了“Loop Prediction”和“Indirect Prediction”部件优化这两种分支指令的预测。此外分支预测单元,还设置了RSB(Return Stack Buffer),当CPU调用一个函数时,RSB将记录该函数的返回地址,当函数返回时,将从RSB中获得返回地址,而不必从堆栈中获得返回地址,从而提高了函数返回的效率。
目前在高性能处理器中,动态分支预测的主要实现机制是CPU通过学习以往历史信息,并进行预测,因而Neural branch predictors机制被引入,并取得了较为理想的效果,本节对这种分支预测技术不做进一步说明。目前指令的动态分支预测技术较为成熟,在高性能计算机中,分支预测的成功概率在95%~98%之间,而且很难进一步提高。






相关推荐