【摘要】:采用直接向Cache行写的方法,PCI设备对存储器写命中一个状态为M的Cache行时,将执行以下操作。CPU通过对FSB监听,发现该写请求在某个Cache行中命中,而且该Cache行的状态为M。HOST主桥将数据直接写入到Cache行中,并保持Cache行的状态为M。但是从具体实现上看,设备直接将数据写入Cache中,还是有相当大的难度。除了需要考虑Cache连接在BSB总线的情况外,在外部设备进行DMA操作时,还需要考虑多处理器系统的Cache共享一致性协议。
在许多高性能处理器中,还提出了一些新的概念,以加速外设到存储器的DMA写过程。如Freescale的I/O Stashing和Intel的IOAT技术。
如图3-8所示,当设备进行存储器写时,如果可以对Cache直接进行写操作,即便这个存储器写命中了一个状态为M的Cache行,也不必将该Cache行的数据回写到存储器中,而是直接将数据写入Cache,之后该Cache行的状态依然为M。采用这种方法可以有效提高设备对存储器进行写操作的效率。采用直接向Cache行写的方法,PCI设备对存储器写命中一个状态为M的Cache行时,将执行以下操作。
(1)HOST主桥将对存储器的写请求发送到FSB总线上。
(2)CPU通过对FSB监听,发现该写请求在某个Cache行中命中,而且该Cache行的状态为M。
(3)HOST主桥将数据直接写入到Cache行中,并保持Cache行的状态为M。注意此时设备不需要将数据写入存储器中。
从原理上看,这种方法并没有奇特之处,只要Cache能够提供一个接口,使外部设备能够直接写入即可。但是从具体实现上看,设备直接将数据写入Cache中,还是有相当大的难度。特别是考虑在一个处理器中,可能存在多级Cache,当CPU进行总线监听时,可能是在L1、L2或者L3 Cache中命中,此时的情况较为复杂,多级Cache间的协议状态机远比FSB总线协议复杂得多。
在一个处理器系统中,如果FSB总线事务在“与FSB直接相连的Cache”中命中时,这种情况相对容易处理;但是在与BSB(Back-Side Bus)直接相连的Cache命中时,这种情况较难处理。下面分别对这两种情况进行讨论,在一个处理器中,采用FSB和BSB连接Cache的拓扑如图3-9所示。(https://www.chuimin.cn)
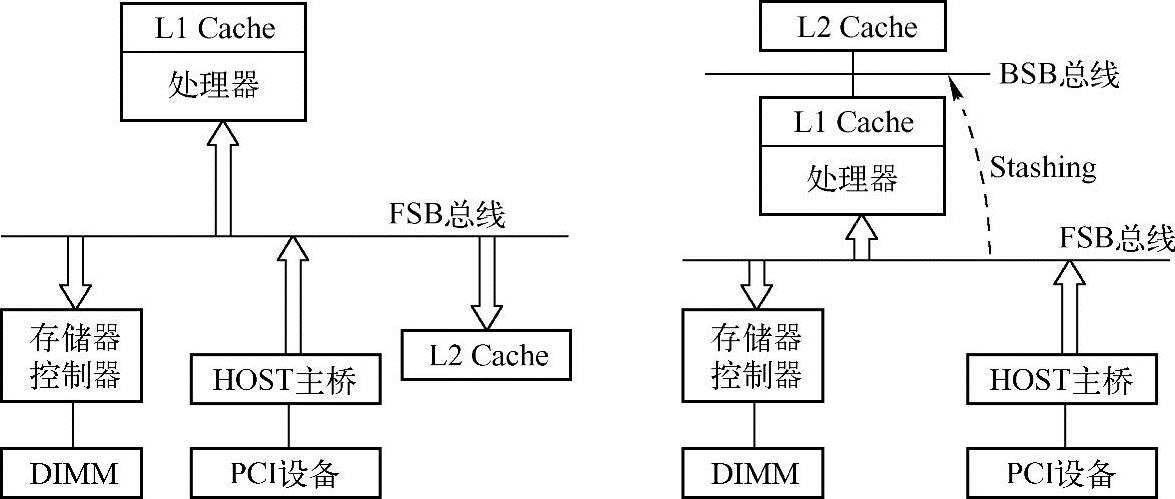
图3-9 采用FSB/BSB进行Cache连接
当采用FSB总线连接L2 Cache时,L2 Cache直接连接到FSB总线上,设备通过FSB总线向L2 Cache进行写操作并不难实现,MPC8548处理器就是采用了这种结构将L2 Cache直接连接到FSB总线上。
但是由于FSB总线的频率低于BSB总线频率,因此采用这种结构将影响L2 Cache的访问速度,为此高端处理器多采用BSB总线连接L2 Cache,x86处理器在Pentium Pro之后的高性能处理器都使用BSB总线连接L2 Cache,Freescale的G4系列处理器和最新的P4080处理器也使用BSB总线连接L2 Cache。
当L2 Cache没有直接连接到FSB上时,来自外部设备的数据并不容易到达BSB总线。除了需要考虑Cache连接在BSB总线的情况外,在外部设备进行DMA操作时,还需要考虑多处理器系统的Cache共享一致性协议。设计一个专用通道,将数据从外部设备直接写入到处理器的Cache中并不容易实现。Intel的IOAT和Freescale的I/O Stashing可能使用了这种专用通道技术,直接对L1和L2 Cache进行写操作,并在极大增加了设计复杂度的前提下,提高了处理器系统的整体效率。
以上对Cache进行直接写操作,仅是Intel的IOAT和Freescale的I/O Stashing技术的一个子集。目前Intel和Freescale没有公开这些技术的具体实现细节。在一个处理器系统中,可能存在多级Cache,这些Cache的层次组成结构和状态机模型异常复杂,本章对这些内容不做进一步说明。







相关推荐