RNN算法对标准层次聚类的合并准则和相似度度量做了相应的改进,从而降低了其复杂度,使其更适用于大规模的数据集。当合并最近邻对得到一个新的簇时,需要重新计算该簇与其他各个簇的相似度,如果通过平均值的距离来度量两个簇的距离,其计算复杂度仅为O,但是由于本书采用的是平均距离,则需要通过更为有效的方法进一步降低复杂度。对于低维数据,还可以通过更为有效的最近邻搜索技术进一步降低复杂度。......
2025-09-29
霍特林(Hotelling)[207]提出了一个可以去掉一个随机向量中各元素间相关性的线性变换,并把它称作“主分量法”。此后,卡胡南(Karhunen)和列夫(Loeve)提出了一种针对连续信号的类似的变换。这种方法派生出了一种离散图像变换的方法。
我们根据角点的坐标可以生成二维向量,可以把这些二维向量当成原理中的随机向量X=(a,b)T处理,其中a和b是角点关于x1轴和x2轴的坐标值。总体的均值向量(边界点)可以通过K个样本向量(角点)来估计:

总体向量的协方差矩阵可以以如下方式用样本近似得到:
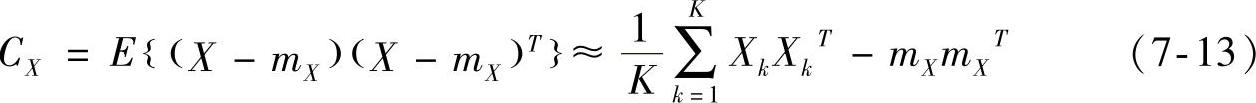
因为CX是实对称的,找到一组n个标准正交特征向量总是可能的。令ei和λi,i=1,2,…,n为特征向量和对应的CX特征值,以降序排布,使λj≥λj+1,j=1,2,…,n-1。令A为一个由CX的特征向量组成其行元素的矩阵,并进行排序,使A的第一行为对应最大特征值的特征向量,而最后一行为对应最小特征值的特征向量。假设把A作为将X的向量映射到用y代表的向量的变换矩阵,就得到了霍特林变换的表达式:

使用式(7-14)的实际结果是需要设置一个新的坐标系统,这个坐标系统以角点总体的质心(均值向量的坐标)为原点,以CX的特征向量所指方向为轴的方向,如图7-5b所示。这个坐标系统清晰地显示出式(7-14)所进行的变换是一种旋转变换,这种变换使用特征向量将数据排列起来,如图7-5c所示。实际上,这种排列正好是数据去相关的机理。另外,由于特征值沿着Cy的主对角线排列,λi是沿着特征向量ei的分量yi的方差,这两个特征向量是正交的。由于这个明显的原因,y轴被称为本征轴[8]。
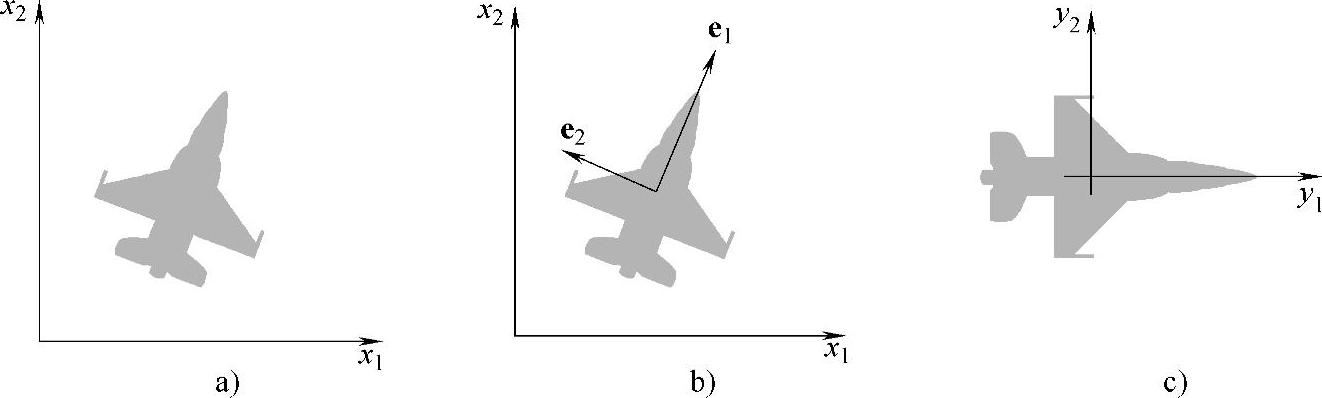
图7-5 用主分量法将目标沿着自身的本征轴对准
a)一个目标 b)特征向量 c)旋转目标
使用主特征向量排列角点的概念在图像描述中起着十分重要的作用。正如前面提到的,目标的描述对于大小变化、平移和旋转变化本应是尽可能独立的。使用目标的主轴校正的能力为消除旋转变化的影响提供了一种可靠手段。特征值是沿着本征轴的方差,并可用于尺寸的归一化。平移带来的影响可以通过将角点的均值设定为中心来解决。(https://www.chuimin.cn)
Huttenlocher等人[208]提出的Hausdorff距离是用来描述两组点集之间相似程度的一种度量,是集合与集合之间距离的一种定义形式。它与许多其他匹配算法不一样,它并不要求目标与模板的简单一致,而是可以针对部分匹配作出良好的反应,因此它本身就具有一定的抗遮挡能力。对有限点集A={a1,a2,…,ap}和B={b1,b2,…,bp},A,B之间的Hausdorff距离定义如下:
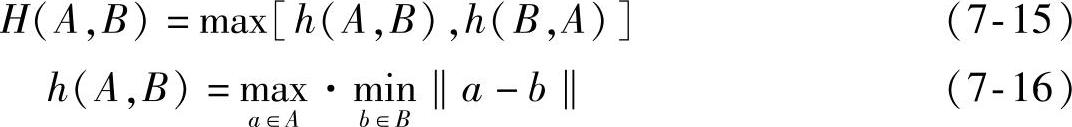
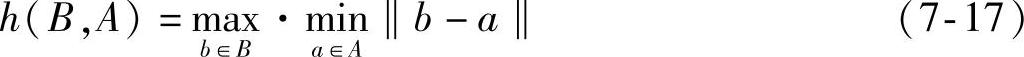
式中,H(A,B)是h(A,B)、h(B,A)中较大的那一个,称为A、B之间的Hausdorff距离;h(A,B)称为点集A到B的有向Hausdorff距离,即点集A中的每个点ai到B集中与其距离最近的点bj之间的距离ai-bj‖进行排序,取这样的距离中的最大值作为h(A,B)的值,同理可得h(B,A);∗‖表示某种距离范数,如欧氏距离。如图7-6所示,Hausdorff距离表征了两个点集之间的最大不相似程度。
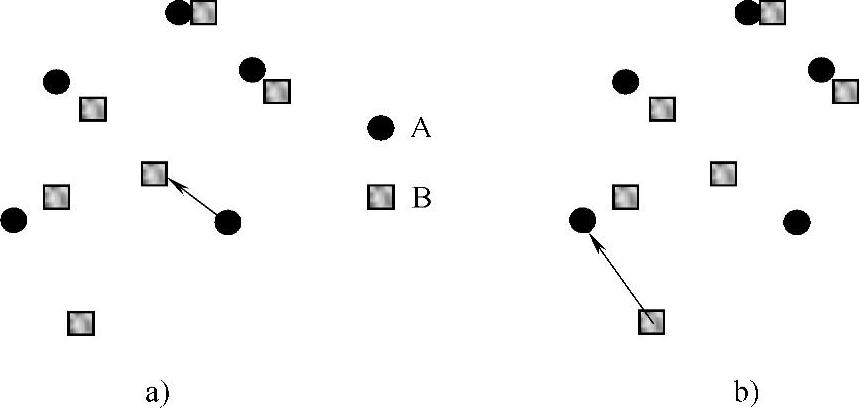
图7-6 Hausdorff距离示意图
a)表示点集A到B的有向Hausdorff距离 b)表示点集B到A的有向Hausdorff距离
在本书的应用中,为了降低噪声的影响,我们使用部分Hausdorff距离,其定义如下:
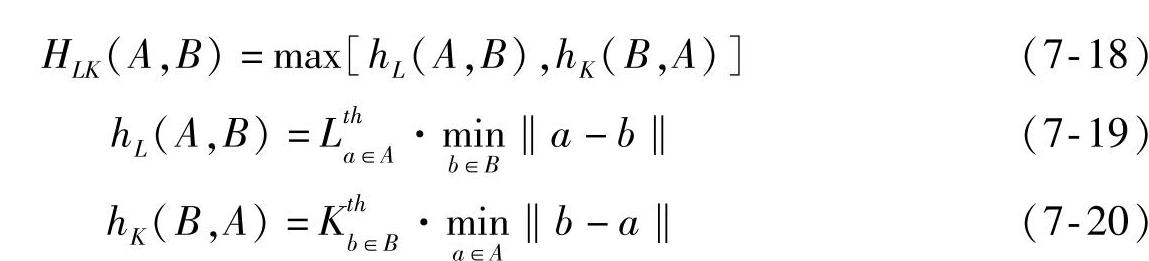
式中,HLK(A,B)仍是hL(A,B)和hK(B,A)中较大的一个。hL(A,B)虽然还是按照ai-bj‖(即A中的每个点ai到B中与其距离最近的点bj之间的距离)进行排序,但不是像h(A,B)那样取全局最大值,而是取第L个值(1≤L≤q,q为A集中点的数目),hK(B,A)同理可得。
通过角点检测算法可以得到待匹配目标和原型的两组特征点集,则目标匹配问题就转化为特征点匹配问题。因为Hausdorff距离的适用形式限制在有限点集内,所以非常适合度量特征点集的相似性。而角点点集经过主分量法处理后,消除了其对尺寸、位置、方位的依赖性,就可以作为Hausdorff距离的匹配元素,对这些元素的相似性进行度量并将此度量值作为目标与原型相似性的依据,如此一来,大大降低了算法的运算复杂度,并减少了噪声对识别效果的影响。
相关文章

RNN算法对标准层次聚类的合并准则和相似度度量做了相应的改进,从而降低了其复杂度,使其更适用于大规模的数据集。当合并最近邻对得到一个新的簇时,需要重新计算该簇与其他各个簇的相似度,如果通过平均值的距离来度量两个簇的距离,其计算复杂度仅为O,但是由于本书采用的是平均距离,则需要通过更为有效的方法进一步降低复杂度。对于低维数据,还可以通过更为有效的最近邻搜索技术进一步降低复杂度。......
2025-09-29

而基于内容的图像检索需要对一类物体进行匹配,比如检索有汽车、飞机、坦克、人群、楼房的图像,这种情况下就需要对具体的局部特征进行组合优化,从而得到对某类物体的理想化表征——原型。原型匹配理论是这样描述知觉加工的:当一种视觉系统收到一个新刺激,该系统就会将它与原先存储的原型进行比较,但并不要求完全相匹配,事实上大致的匹配就可以了[13]。为了实现从模板匹配到原型匹配的转变,我们引入了相关反馈技术。......
2025-09-29

这一模型意味着在我们的知识基础中,已经存储了数以百万计的不同模板——每一个可以辨识的不同物体或模式,都有一个与之匹配的模板存在。本书结合局部特征的特点和模板匹配的原理,提出了一种图像检索方法。如果局部特征和模板匹配的数量越多,则该幅图像和查询图相似的程度就越高。显然,模板匹配并不完全适合知觉原理的实际应用。......
2025-09-29

对于双窗系统,EN不再恒等于1,但具有“倒余弦”形状,这样W-O分析谱中在每点都产生旁瓣。同古典谱估计方法相比,由于AR模型是一个有理分式,因而估计出的谱比古典谱估计法估计出的谱平滑。由式易知,X0在k=0时的权值为N,即阶数越高,W-O谱线分辨力越强。图6-9 传统信号加窗与W-O谱分析由图6-9可以看出,用W-O方法得到的信号频谱比用传统加窗方法具有更少、更低的旁瓣干扰。......
2025-09-29

现有的图像检索方式主要分为两种:基于文本的图像检索和基于内容的图像检索。针对以上两点问题,本书对局部特征提取技术和相关反馈技术进行了深入的研究分析,提出了一种基于局部特征的图像检索方法。......
2025-09-29

由于半导体制造系统属于典型的Np-hard 问题, 传统的运筹学方法会带来繁杂的数据运算从而很难进行优化, 在实际应用中通常是寻求计算效率高、 优化效果较好的启发式算法, 本书给出求解该目标函数的一种启发式优化算法, 具体启发式算法流程图如图4-5 所示, 其步骤如下:Step 1: CCij信息初始化,t =0;Step 2: Dik需求招标值下达,wi 权重系数给定( i =1, 2, …......
2025-09-29

设某一属性的所有值的数据集为S,其平均值为Smean。根据这些想法,提出一种基于聚类的全局特异数据挖掘方法。构架仍由挖掘特异属性和挖掘特异记录两个层次构成。从原则上讲可以采用任何基于距离的聚类算法对S进行聚类,采用的聚类算法的效果好,可以减少后续的计算量。图3.2SimC聚类算法可以看出,k是控制聚类半径Cd的。现在根据式(3.9)计算每个类的特异因子,记为CPF。显然,CPF越小的类,其中的元素是特异数据的可能性越小。......
2025-09-29

为寻找更为理想的基窗函数,借助LMS算法思想提出了“基于LMS准则以apSW为模型的基窗函数设计方法”。图3-21 余弦基神经自适应网络图3-21 余弦基神经自适应网络图3-22 apSW基窗LMS设计算法按照流程图,设计截止频率为π/4的32阶低通apSW的窗函数F。......
2025-09-29
相关推荐