相对于PE、PVDC产品,PVC保鲜膜透明性好,不容易破裂,同时具有很好的黏性。DEHA是一种添加在合成树脂材料中可增加产品柔韧性及弹性的物质,在PVC保鲜膜中含量为40%~50%。PE保鲜膜与PVC保鲜膜的鉴定走进超市,特别是冷冻食品及水果蔬菜专柜时,就会发现这些食物往往都是被保鲜膜牢牢地包裹住的。PE保鲜膜对人体没有毒害,但用PVC保鲜膜包装熟食对人体有毒害作用。合格的PE保鲜膜在超过110℃时会出现热熔现象,产生对人体有害的物质。......
2023-07-04
目标识别系统中分类器的作用是:根据特征提取器得到的特征向量来给一个被测对象赋一个类别标记[52]。分类器的设计方法可以分为生成(Generative)方法和判别(Discriminative)方法两类。生成方法是根据类别出现的先验概率和条件概率来估计目标的类别概率,它将分类器设计问题转化为了概率密度估计问题,其代表是朴素贝叶斯分类器(Naive Bayesian Classifier,NBC);而在判别方法中,将每个目标视为整个特征空间中的一个点,认为不同的类别是特征空间中不同的区域或子空间,需要找到一条决策边界把属于不同类别的点分开,其中最具代表性的是支持向量机(Support Vector Machine,SVM)和神经网络(Neural Network,NNet)。本章实验主要选用了朴素贝叶斯和支持向量机两种分类器,关于它们的基本原理和具体实现方法,在本书的3.5节已有介绍,此处不再赘述。
实验1:视觉单词库构造方法对比分析
为了验证利用聚类算法构造视觉单词这一途径的有效性,本章将RNN凝聚聚类算法与划分方法中的k-平均值和k-中心点聚类应用于同一样本集,并比较最终的分类效果。该实验从60幅图片(小汽车图像)中共提取出19127个局部特征(用高斯差分算子检测,并用SIFT描述子描述为128维的模式向量)用以构造视觉单词库,利用支持向量机分类器(线性核函数)对小汽车图像和建筑物图像进行分类测试,得到单词库规模为200—1800之间的正确率,该评估指标是在相等错误率(EER)下的分类效果,对图像进行向量空间模型表示时用的是词频权重。
如图6-7所示,由于RNN凝聚聚类算法得到的簇相对紧致,总体来说要比划分方法中的两种聚类算法性能好。关于视觉单词库的规模,在200—800之间随着视觉单词数量的增加分类效果得到了明显的改善,在800以上凝聚聚类算法相对稳定,k-平均值和k-中心点方法则会出现波动,这是因为划分方法经常以局部最优结束。
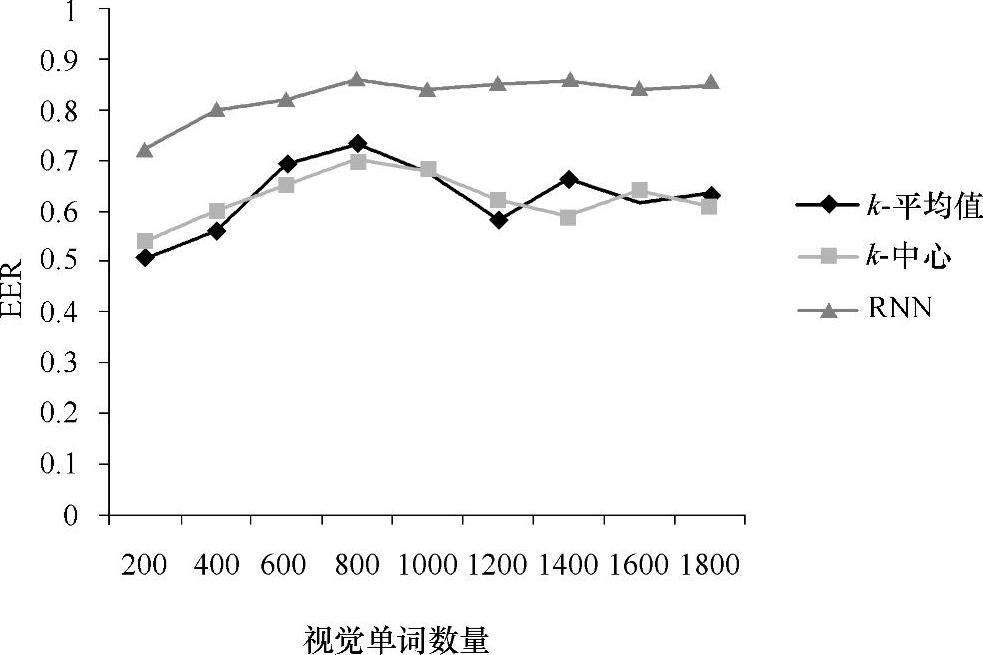
图6-7 不同视觉单词库构造方法的性能
实验2:图像数量和分类方法的效果分析
图像目标分类效果在受到视觉单词数量影响的同时,也和生成视觉单词库所用的图像数量有关。本实验从40幅图像提取出的局部特征是10411个,70幅图像得到局部特征21577个,而100幅图像的局部特征数目达到39350个。在一定规模之内,从姿态各异的图像目标中提取越多的局部特征,构造出的视觉单词库内容就更为丰富,并且相应的视觉单词(原型特征)对分类来说更有区分性。
如图6-8所示,实验采用视觉单词的数量为800个,构造视觉单词库的图像为30~100个的时候,用朴素贝叶斯算法和支持向量机分别进行分类的效果。可以看出,在达到60幅图像的规模之后,图像的增加不再带来分类效果的明显改善;该实验的结果也简单证实了支持向量机在模式分类中的优越性能。

图6-8 不同样本数量和分类方法的效果
实验3:特征权重对分类效果的影响
采用不同的特征权重类型对分类的最终效果会有较大的影响,本章节将对布尔、绝对词频(TF)和TF-IDF三种特征权重计算方法进行实验对比。实验采用支持向量机(线性核函数)对8种图像目标分别进行二分类,求取每次分类的查准率和查全率。由于样本在所有类别中分布均匀,计算出的宏平均查准率和查全率等于微平均查准率和查全率。如图6-9的RPC曲线所示,该实验中布尔权重效果较差,而TF和TF-IDF权重效果相差不大。
由于用0、1来代表该视觉单词是否在图像目标中出现,布尔权重无法体现视觉单词在目标中的作用程度,因而分类效果显然不如更精确的TF方法。这从理论上讲,TF-IDF作为一种相对词频权重,应当比TF的性能好,因为TF虽然体现了视觉单词的频率,但无法体现低频视觉单词的区分能力——有些视觉单词频率虽然很高,但分类能力很弱(比如大多数目标共有的特征或背景特征),有些视觉单词虽然频率较低,但分类能力却很强。但是从实验结果可以看出,TF-IDF的效果不够理想,这一方面是因为图像目标分类中训练集的数目并不够大,本章在一次实验中训练样本只有200幅图像;另一方面很有可能是图像目标的向量空间模型表示维度较低,本章实验采用800维向量,这远远低于文本分类中所用的模式向量的维度。
实验4:特征选择对分类效果的改善
特征选择在降低模式向量维数的同时保留了对分类有用的特征,本章节将通过图像频率(IF)、χ2统计量(CHI)方法、信息增益(IG)法和互信息(MI)法对图像特征进行筛选并进行分类效果对比。实验采用支持向量机(线性核函数)对图像目标进行二分类,在目标表示时用绝对词频计算特征权重,通过特征选择将视觉单词的数量从800减少至450,步长为50,测试每种方法在相等错误率(EER)下的分类正确率。如图6-10所示,在将特征维数降到600~700时大多数方法的效果最好,而总体看来基于互信息的特征选择方法性能较好。基于图像频率的特征选择方法最为简单易行,但该方法直接去除低频特征对分类效果产生不利影响。
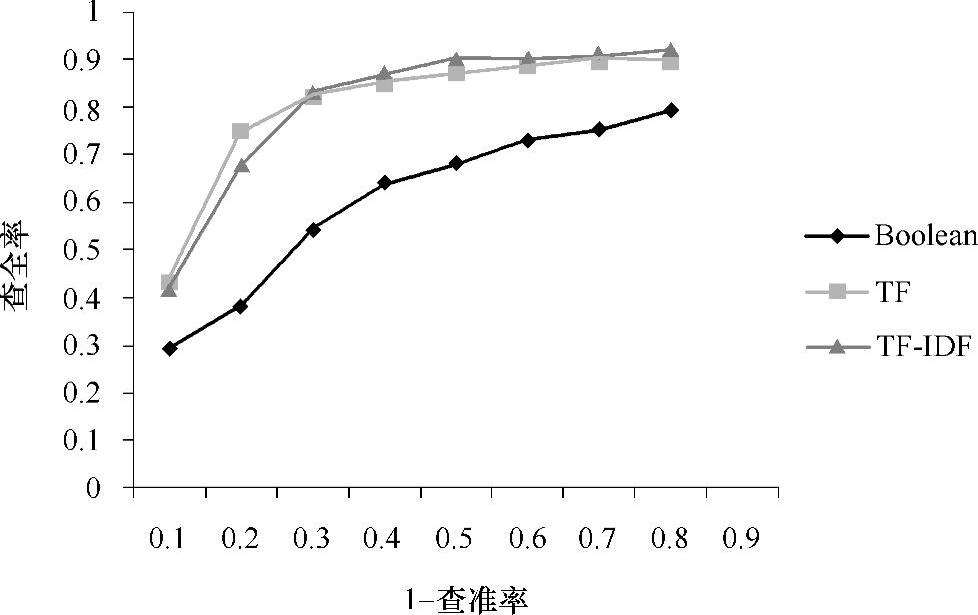
图6-9 采用不同特征权重的分类效果
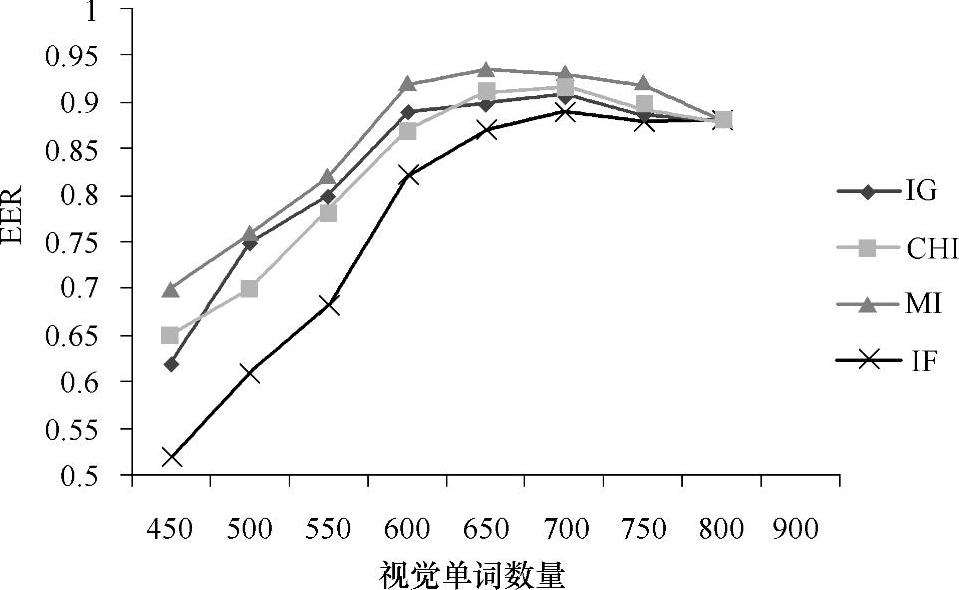
图6-10 特征选择后的分类性能
实验5:与相关文献的分类性能对比
近几年,国内外许多学者都在广泛关注利用局部特征进行图像目标识别这一研究方向。为了更为直观地比较Weber、Opelt等人提出的图像目标分类算法(参见参考文献[50],[127],[195]-[199])与本书提出的算法的性能差异,进行如下对比实验。为了相关算法保持一致,实验所用的摩托车和小汽车(背面视图)两类图像都选自Caltech图像库,算法的正确率是在相等错误率(EER)时计算所得的。从表6-3可以看出,与其他算法的最佳效果相比,本书算法的性能指标稍逊于Zhang提出的方法,总体看来正确率还是比较高的,可以说明本书算法的可行性。
表6-3相关文献算法与本书算法对比

有关图像目标的表示与识别的文章

相对于PE、PVDC产品,PVC保鲜膜透明性好,不容易破裂,同时具有很好的黏性。DEHA是一种添加在合成树脂材料中可增加产品柔韧性及弹性的物质,在PVC保鲜膜中含量为40%~50%。PE保鲜膜与PVC保鲜膜的鉴定走进超市,特别是冷冻食品及水果蔬菜专柜时,就会发现这些食物往往都是被保鲜膜牢牢地包裹住的。PE保鲜膜对人体没有毒害,但用PVC保鲜膜包装熟食对人体有毒害作用。合格的PE保鲜膜在超过110℃时会出现热熔现象,产生对人体有害的物质。......
2023-07-04

设计分类器是目标分类的主要任务和核心研究内容之一。这种情况下,还得调用单分类器方法,将其类别设置为相似度最大的那个类别。第一种分类器常用于目标匹配识别,其性能取决于相似度或距离度量的设计,后两种分类器基本对应于生成模型和判别模型。......
2023-06-28

按照式,泥沙粒径分布的第P 个百分点对应的粒径Dp可确定为:式描述了D50t和D50的关系。考虑到Qs50∝CD5-0b和QsDe∝CDe-b,可变代表粒径可表示为:图2-10粒径等于输移泥沙中值粒径的床沙所占百分比 图2-10粒径等于输移泥沙中值粒径的床沙所占百分比 上文已经提到,Einstein 和Ackers-White公式曾建议使用D35作为非均匀沙输沙能力计算的代表粒径。......
2023-06-22

如图2.21所示,当水泥掺入比为10%时,掺入2%石膏,28d龄期强度可增加20%左右,60d龄期可增加10%左右,90d龄期已不再增加强度;掺入2%氯化钙、28d龄期强度可增加20%左右,90d龄期强度反而减少7%;掺入0.05%三乙醇胺,28d龄期强度可增加45%左右,90d龄期可增加18%左右,90d龄期可增加强度14%。因此,三乙醇胺不仅能大大提高早期强度,而且对后期强度也有一定的增强作用,弥补了单掺无机盐降低后期强度的缺陷。图2.21外掺剂对水泥土强度的影响......
2023-06-26

电渗现象是指在外加电场作用下、液体通过多孔固体的运动现象。运行经验表明,电缆或变压器的绝缘层受潮通常是从外皮或外壳附近开始的。电缆及变压器在不同极性的电压作用下,水分在绝缘层中的移动情况如图4-10所示。......
2023-06-27

观赏型体育消费直接影响体育竞赛表演业的发展,是一个国家体育发展水平的重要标志。纵观体育消费市场我们可以发现,从事观赏型体育消费的人数非常有限,且大多是真正的体育迷才会在体育赛事方面花费金钱。这些都是体育消费态度的变化。......
2023-10-17

良性冲突是指双方目的一致而手段或途径不同的冲突。恶性冲突往往是由于双方目的不一致而造成的。这类冲突对企业目标的实现往往是不利的。趋避式冲突,又称“正负冲突”。但对冲突基本类型的了解无疑有助于进一步了解更复杂的冲突情况。组织中的非正式组织和正式组织之间、直线与参谋之间以及委员会内部之间的冲突是最为典型的团体冲突。......
2023-08-02

茶作为一种饮料,其饮用价值是通过水的溶解而实现的,因此水的优劣直接影响茶汤的质量。我国自古以来就十分讲究茶叶冲泡水的选择,甚至把“石泉佳茗”视为“人生清福”。古人对泡茶用水的选择,归纳起来是两条标准:一是水质;二是水味。饮用水应当质地洁净,烹茶用水尤应清净。据科学家的不断研究分析,发现茶叶中的化学成分是组成茶叶色、香、味的物质基础,多数能在冲泡过程中溶解于水,从而组成了茶汤的色泽、香气和滋味。......
2023-08-13
相关推荐