大量的视觉单词就组成了视觉单词库,在一些文献中也称之为码书。用视觉单词作为向量空间模型中的特征项,就可以解决目标图像的表示问题,从而实现基于向量空间模型的目标分类了。对局部特征进行聚类是构造视觉单词的一种有效途径,因为聚类分析的目的就是将物理或抽象对象的集合分组成由类似的对象组成的多个类[128]。k-means算法是根据预定的类别数目k随机地选取k个对象作为初始的簇中心。......
2023-06-28
视觉单词权重用于衡量某个视觉单词(特征项)在目标表示中的重要程度或者区分能力的强弱。权重计算的一般方法是利用训练集样本的统计信息,主要是词频,给视觉单词赋予一定的权重。注意,“词频”以及后面提到的“文档频度”,都是在文本分类中产生的,在本章节中用图像目标相关的概念进行理解即可,不再特意进行替换。
本书参阅相关文献,将一些常用的权重计算方法归纳为表6-2所示的形式。表中各变量的说明如下;wij表示特征项ti在目标Tj中的权重,tfij表示特征项ti在训练样本Tj中出现的频度;ni是训练集中出现特征项ti的样本数,N是训练集中总共的样本数;M为特征项的个数,nti为特征项ti在训练样本中出现的次数。
表6-2特征权重的计算方法
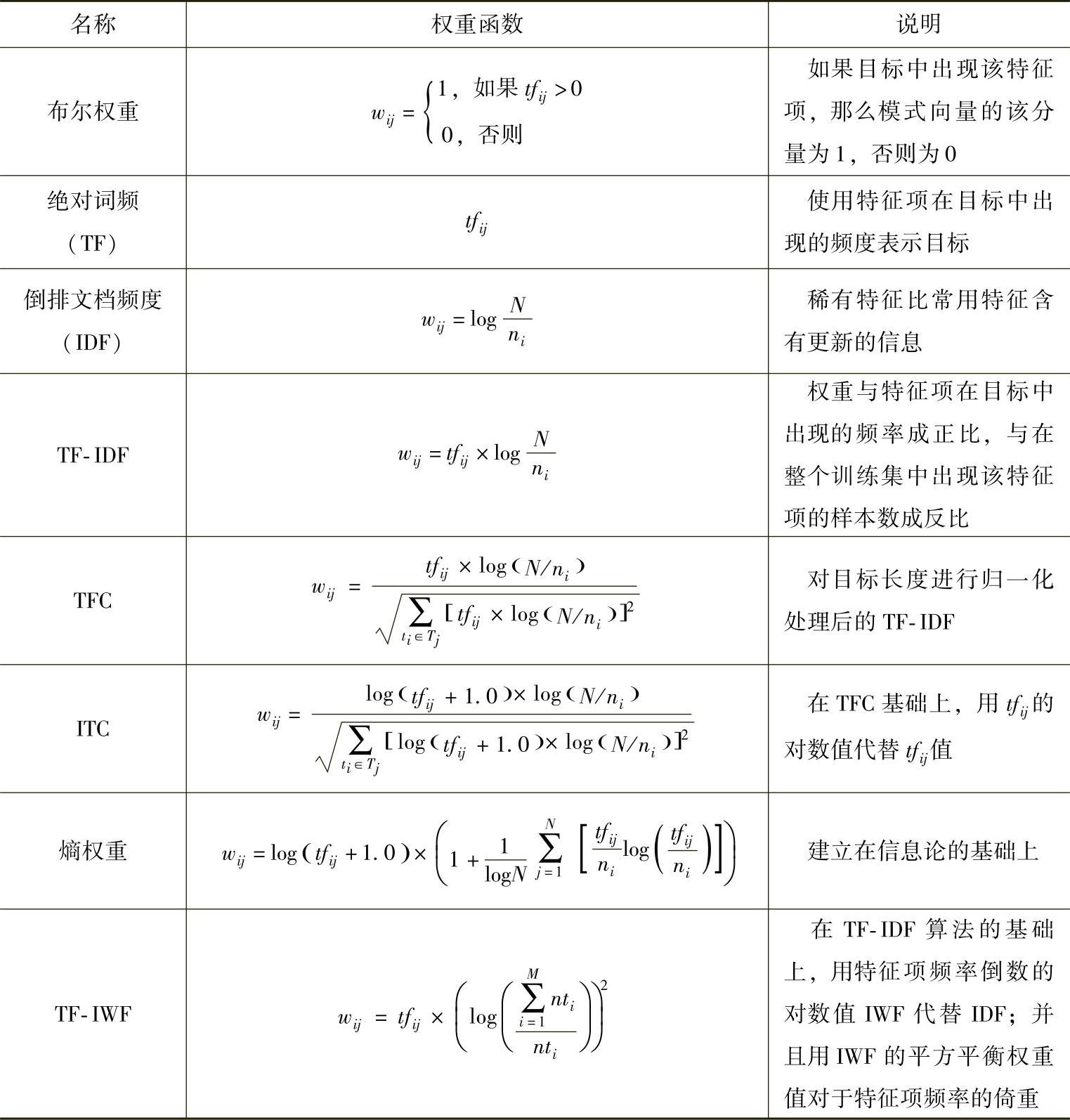
由于布尔权重(Boolean Weighting)计算方法无法体现特征项在文本中的作用程度,因而在实际应用中0、1值逐渐地被更精确的特征项的频率所代替。在绝对词频(Term Frequency,TF)方法中,无法体现低频特征项的区分能力,因为有些特征项频率虽然很高,但分类能力很弱(比如大多数目标共有的局部特征或背景特征),而有些特征项虽然频率较低,但分类能力却很强。
倒排文档频度(Inverse Document Frequency,IDF)法是文本分类中计算词与文献相关权重的经典方法,其在信息检索中占有重要地位。该方法在实际使用中,常用公式L+log ((N-ni)/ni)代替,其中,常数L为经验值,一般取为1。IDF方法的权重值随着包含某个特征的样本数量ni的变化呈反向变化,在极端情况下,只在一个样本中出现的特征含有最高的IDF值。
本章使用的特征权重计算方法TF-IDF,该方法的公式有多种表达形式,TFC方法和ITC方法都是它的变种。实际应用中,有一种比较普遍的TF-IDF公式:
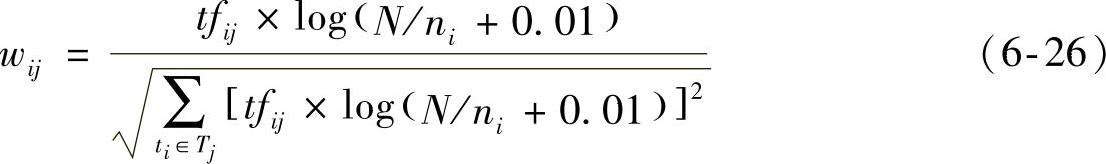
或

TF-IWF(Inverse Word Frequency)权重算法也是在TF-IDF算法的基础上提出的,其不同之处在于:
1)TF-IWF算法中用特征频率倒数的对数值IWF代替IDF;
2)TF-IWF算法中采用IWF的平方来平衡权重值对于特征频率的倚重,不像IDF中采用的是一次方,给了特征频率太多的倚重。
此外,还有很多特征权重的计算方法,可以参阅文本分类的相关文献,这里不再一一列举。需要说明的是,权重计算方法与特征提取方法有着一定的关联,而很多文献引入的新的计算变量实质上都是考虑特征项在整个类中的分布问题。因此,需要进一步进行理论研究,获得更一般的有关特征权重确定的结论,而不是仅仅从不同的角度定义不同的计算公式。
有关图像目标的表示与识别的文章

大量的视觉单词就组成了视觉单词库,在一些文献中也称之为码书。用视觉单词作为向量空间模型中的特征项,就可以解决目标图像的表示问题,从而实现基于向量空间模型的目标分类了。对局部特征进行聚类是构造视觉单词的一种有效途径,因为聚类分析的目的就是将物理或抽象对象的集合分组成由类似的对象组成的多个类[128]。k-means算法是根据预定的类别数目k随机地选取k个对象作为初始的簇中心。......
2023-06-28

系统标定等研究内容一般也在这个层次上进行。它要求图像技术工作在一个整体的框架下进行。图像处理是底层操作,它主要在图像的像素级上进行处理,处理数据量大。图1.3 图像工程的三层次示意......
2023-11-24

计算机视觉测量技术以图像传感器为手段检测空间物体的空间三维坐标,进而检测物体的尺寸、形状和运动状态等。美国、加拿大、日本等发达国家早在20世纪60年代后期就已经开始了计算机视觉测量技术的研究。直到20世纪90年代,随着计算机技术的发展成熟,计算机视觉测量技术逐渐成为一个研究热点。......
2023-11-24

Robert将环境限制在所谓的“积木世界”,即周围物体都是由多面体组成的,需要识别的物体可以用简单的点、直线、平面的组合表示。1977年,Marr教授提出了不同于“积木世界”分析方法的计算机视觉理论——Marr视觉理论。......
2023-11-24

合理的反射镜长度设计是系统的最基本要求。设反射镜M2R的最短长度为lmin,在△OBC及△O2LCD中,由正弦定理有由式和式可得,反射镜M2R的最短长度为2.基线距离B的计算单摄像机虚拟立体视觉的基线距离是两个虚拟摄像机光学中心和之间的距离,因此基线距离为从式可以看出,基线距离由四个因素决定:光学反射镜的摆放角度α和β、摄像机光学中心的Z轴坐标d及M2R与X轴交点的坐标L。......
2023-11-24
计算机视觉检测技术是计算机视觉在检测领域的应用,即用计算机代替人眼实现“测量与判断”,实现生产、生活中的“检”与“测”任务。综上所述,计算机视觉检测技术按检测性质和应用范围可以划分为定性检测和定量检测两类系统如图1.6所示。定量的视觉检测又称为视觉测量。......
2023-11-24

近年来,车载视觉里程计技术已经获得了许多研究成果。3)透视摄像机与全方位摄像机从所使用的摄像机类型来看,视觉里程计又可分为透视摄像机系统与全方位摄像机系统。视觉里程计中的两帧方案典型地来自SFM算法,也就是利用连续两帧图像的特征信息,来求解位姿变换。经典的视觉里程计系统大多基于这种计算框架。5)纯视觉系统与混合系统根据前文定义,仅仅依靠视觉信息输入的里程计系统被称为纯视觉系统。......
2023-09-19

一个新注册的网站,经过一些宣传之后,通常Google就会对其进行收录,但赋予的权值并不会太高。在明白了百度的收录规则以后,我们便可以根据其特点做出相关的应对策略。站点的稳定性差同样会导致百度收录变少或没收录。网站空间不稳定,动不动打不开网站,百度连续两次以上更新都无法抓到相应信息,那么你肯定要被从数据库清理,因为百度以为你的站已经关闭,或者相关页面不存在了。......
2023-11-19
相关推荐