【摘要】:如图5-2所示,对于特征点数量达到10000、维度为5~25的数据检索中,按照BBF算法改进的搜索策略很大程度上提高了检索效率,而标准的K-D树搜索策略在数据维度达到10后其效率便明显下降了。图5-2 BBF算法与K-D树的搜索时间代价本书设定的约束条件是检查前200个最邻近候选节点,该算法在搜索速度提高了2个数量级的同时,平均只丢失5%的特征对,这对于一般的图像检索来说是可以容忍的。
用穷举法搜寻最邻近点以及次邻近点,可以得到最精确的结果。但是由于本书所用的特征空间一般都高达128维以上,加之复杂图像的局部特征数量比较多,搜索算法的效率显然成为了整个系统的一个瓶颈。
1.K-D树搜索策略
标准K-D树是Friedman等人[178]提出的一种高维二叉树,K表示空间的维数,在其上可实现对给定特征点的快速最近邻查找。若某K-D树的结点数目为N,则在它上面的最邻近节点的平均计算复杂度为O(lgN)。其后又相继提出了K-D树的1+ε近似最近邻搜索算法(ANNS),其主要思想是在搜索时只查询那些与给定特征点的距离小于当前最近距离1/(1+ε)倍的点,此时搜索完成时返回的点未必是真实的最近邻点(除非ε=0),但是即使当ε取的较大(如ε=3时),所返回的点仍然有50%的机会是真实的最近邻点,而且在平均意义上它们到目标点的距离只是真实最近邻点到目标点的距离的11.5倍,取得的加速比却可以达到50倍以上。
在数据维数较低的时候,K-D树搜索方法比较有效。在更高维的数据空间中将会有更多的分类结果接近目标真实数据,此时使用K-D树进行搜索的话,效率将会急剧下降。本书所用的特征空间一般都高达128维以上,为此本书使用了Beis和Lowe提出的Best-Bin-First(BBF)算法[146],它对常规的K-D树搜索方法进行改进,从而实现较快的匹配点搜索。
2.基于BBF算法的搜索策略
在高维数据搜索空间中,K-D树搜索的结果仅仅只有很少的一部分满足邻近原则,为了加快搜索速度,可以通过减少搜索节点来缩小搜索范围。这需要使用一个基于堆的优先级队列,将搜索空间的节点按照与待查询节点的距离来进行排序。当搜索到的节点符合设定的约束条件,则记录到优先级队列中去,从而获取下一个候选节点的信息(包括该节点在当前树的位置和到待查询节点的距离)。当一个最邻近点被搜索到后,则从队列的队首删除一项,然后继续搜索包含最近邻节点的其他分支。(https://www.chuimin.cn)
如图5-2所示,对于特征点数量达到10000、维度为5~25的数据检索中,按照BBF算法改进的搜索策略很大程度上提高了检索效率,而标准的K-D树搜索策略在数据维度达到10后其效率便明显下降了。
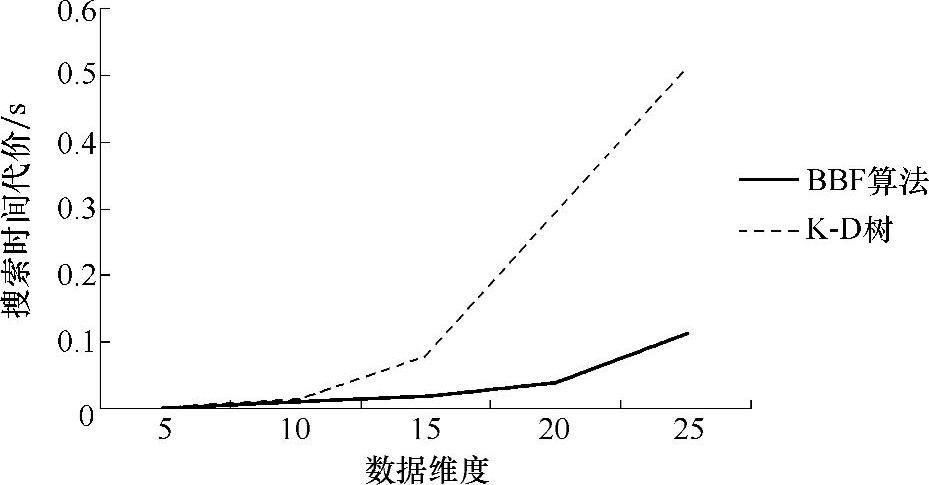
图5-2 BBF算法与K-D树的搜索时间代价
本书设定的约束条件是检查前200个最邻近候选节点,该算法在搜索速度提高了2个数量级的同时,平均只丢失5%的特征对,这对于一般的图像检索来说是可以容忍的。当距离非常相近的特征点需要进一步甄别的时候,BBF算法的搜索效率会受到制约,但是本书剔除了与最近邻点和次近邻点距离比值大于0.8的特征对,这就基本上避免了这一困境。






相关推荐