基于聚类分析的分类与后面几节所述的有监督学习分类的不同之处在于,它要划分的类是未知的,也就是说事先并不知晓要把目标分为哪几个具体的类别。为了达到全局最优,基于划分的聚类会要求穷举所有可能的划分。它也基于标准的统计数字自动决定聚类的数目,考虑“噪声”数据和孤立点,从而产生健壮的聚类方法。高维数据聚类分析是聚类分析中一个非常活跃的领域,同时也是一个具有挑战性的工作。......
2023-06-28
人工神经网络是在对人脑神经网络的基本认识的基础上,用数理方法从信息处理的角度对人脑神经网络进行抽象,建立的某种简化模型[113]。其中,反向传播网络(Error Back Propagation Neural Network)是迄今为止应用最广泛的一种神经网络,它是使用BP算法进行学习的多级非循环网络。BP算法在于利用输出层的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,这样就形成了将输出端表现出的误差沿着与输入信号相反的方向逐级向网络的输入端传递的过程。BP算法结束了多层网络没有训练算法的历史,并被认为是多级网络系统的训练方法,它有很强的数学基础,故其连接权的修改是令人信服的。
1.三层BP网络设计
BP网络的结构设计主要是解决设几个隐含层和每层设几个节点的问题。对于这类问题,不存在通用性的理论指导,但神经网络的设计者们通过大量的实践已经积累了不少经验。因为已有结果表明一层隐含层已经足够近似任何连续函数,故图像目标识别系统常常采用三层BP神经网络。第一层输入层PE(处理单元)的数量通常由应用来决定,它可以等于特征向量的维数;第二层隐含层的PE数量则是设计时需要选择的,由于不知道确定神经网络内部层次中间节点数目的规则,因此这个数目一般基于以前的经验或任意指定并通过检验来完善。
如图3-3所示,特征向量的维数N即为BP网络的输入层节点数;中间隐含层的神经元数目确定为(N+No)/2(输入和输出层神经元的平均数)。通常为了减少过度训练的危险,需要将这个数量尽量减少,但是太少又会使网络无法收敛到一个对复杂特征空间恰当的划分,所以网络收敛后,一般可以减少PE的数量再进行训练会得到更好的效果。输出层的节点数与模式类的数目一致,从上到下的No个节点代表各个类别ωj(j=1,2,3,4)。在设定网络结构后,我们对整个网络使用同样形式的“S”激活函数,权值被初始化为带有零均值的小随机数,然后使用模型投影图的相应模式向量对网络进行训练。输出节点在训练期间是受到监控的。对类ωi的所有训练模式,与所求类一致的输出节点必须为高(≥0.95),而同时,所有其他节点必须为低(≤0.05)。
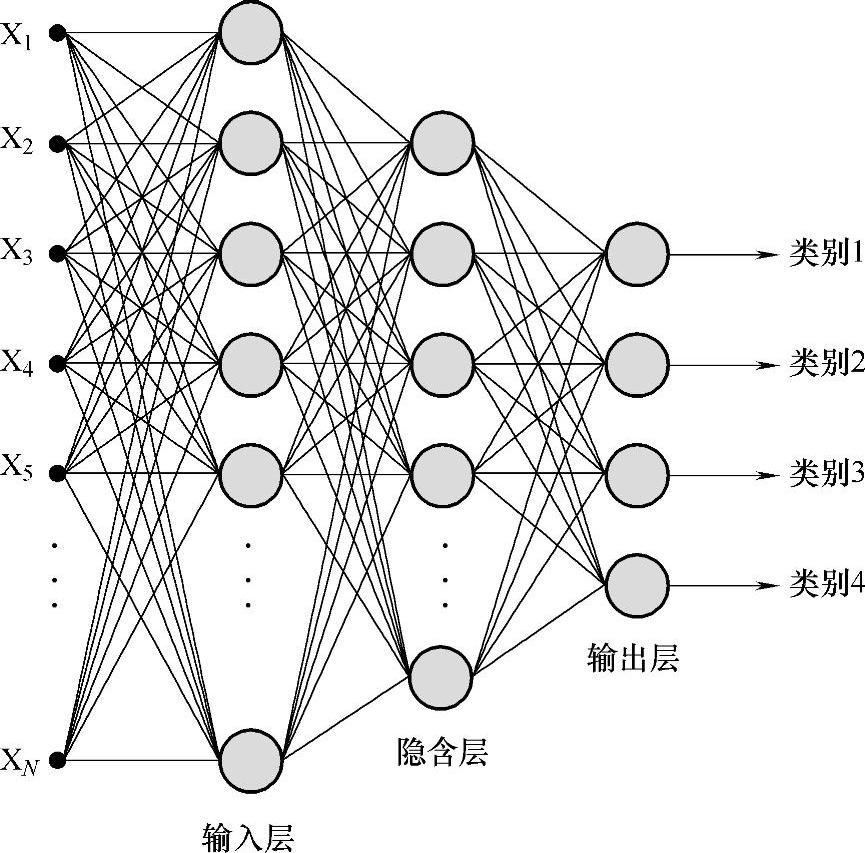
图3-3 用于目标分类的三层BP网络
2.训练方法的改进
BP网络接受样本的顺序会对训练的结果有较大的影响。比较而言,它更“偏爱”较后出现的样本:如果每次都按照(x1,y1),(x2,y2),…,(xs,ys)所给定的顺序进行训练(s为样本数目,xi为输入向量,yi为输出向量,i=1,2,…,s),在网络学习完成投入运行后,对于与该样本序列较后的样本较接近的输入,网络所给出的输出的精度将明显高于与样本序列较前的样本较接近的输入对应的输出的精度。
实际上,按照这种方法进行训练,有时甚至会引起训练过程的严重抖动,更严重的,它可能使网络难以达到用户要求的训练精度。这是因为排在较前的样本对网络的部分影响被排在较后的样本的影响掩盖掉了,从而使排在较后的样本对最终结果的影响就要比排在较前的样本的影响大。这表明,虽然知识的分布表示原理告诉我们,信息的局部破坏不会对原信息产生致命的影响,但是这个被允许的破坏是非常有限的。此外,算法在根据后来的样本修改网络的连接矩阵时,进行的是全面修改,这使得“信息的破坏”也变得不再是局部的。这正是BP网络在遇到新内容时,必须重新对整个样本集进行学习的主要原因。
因此,在训练网络的时候,本书采用随机抽取的方法选取样本。在一轮训练过程中,每次都从s个样本中随机选取一个样本进行训练,直到所有s个样本全部都被选取过。系统进行训练之后,使用在训练阶段中设定的参量对模式进行分类。在标准操作中,所有反馈路径是不连通的。任何输入模式允许通过不同层进行传播,并且模式被划归为高的节点输出所属的类。此时,其他所有节点输出为低。如果被标记为高的节点不止一个,或没有节点输出被标记为高,则可选的做法是,声明进行了错误的分类或简单地将模式划归输出节点的类并赋予最大值。
有关图像目标的表示与识别的文章

基于聚类分析的分类与后面几节所述的有监督学习分类的不同之处在于,它要划分的类是未知的,也就是说事先并不知晓要把目标分为哪几个具体的类别。为了达到全局最优,基于划分的聚类会要求穷举所有可能的划分。它也基于标准的统计数字自动决定聚类的数目,考虑“噪声”数据和孤立点,从而产生健壮的聚类方法。高维数据聚类分析是聚类分析中一个非常活跃的领域,同时也是一个具有挑战性的工作。......
2023-06-28

(一)非模糊化过程BP神经网络输出的结果也是位于0~1之间的值,并不是真实的电力负荷值,因此,本步骤就是将模糊值转化为真实值,可以用以下公式来实现式中L'为真实的电力负荷值,l'为神经网络的输出值。......
2023-08-25

BP神经网络即反向传播网络,它是前向网络的核心部分,也是人工神经网络的精华部分。BP神经网络是目前应用最广的神经网络之一,BP神经网络是由一个输入层、一个或多个隐层以及一个输出层组成,上下层之间实现全连接,而每层神经元之间无连接。......
2023-08-23

朴素贝叶斯分类器进行目标分类的基本思想是利用特征项和类别的联合概率来估计给定目标的类别概率。理论上,朴素贝叶斯分类器与其他分类方法相比具有最小的误差率。但是该模型在分类识别中假设特征项之间相互独立,而这个假设在实际应用中往往是不成立的,这给朴素贝叶斯分类器的正确分类带来了一定影响。因此,近年来大量的研究工作致力于改进朴素贝叶斯分类器,主要集中在选择特征子集和放松独立性假设在两个方面。......
2023-06-28

Matlab语言是MathWorks公司推出的一套高性能计算机编程语言,集数学计算、图形显示、语言设计于一体,其强大的扩展功能为用户提供了广阔的应用空间[6]。它附带有30多个工具箱,神经网络工具箱就是其中之一,其中BP神经网络的训练使用了Neural Networks Toolbox for Matlab。打开Matlab软件,会看到软件界面。在BP神经网络训练时,参数不同,最后网络训练的性能都不同。......
2023-08-23

基于规则的分类器利用IF-THEN规则集进行分类。如一个规则R 1可以表示为:R 1:IF age=youth AND student=yes THEN buys_computer=yesR 1也可以表示为:R 1:^=>其中,IF部分或=>前面的部分称为前件,后一部分称为后件。那么,覆盖率和精度的定义如式(4.1)和式(4.2)。当X只满足规则集中的一个规则R 1时,就可以判定X属于R 1后件的类别。后件为同一类别的规则不需排序,因为它们判断的结果不会有冲突;在基于规则的排序策略中,规则按其前件的质量排序。......
2023-06-16

1943年,心理学家Mcculloch和数学家Pitts合作提出形式神经元的数学模型,成为人工神经网络研究的开端。神经网络的原始模型是1958年提出的感知器模型,只有一个输出节点,它相当于单个神经元,主要用于模式分类。几乎所有神经网络学习算法都可以看做Hebb学习规则的变形。图2.12多层前馈网络结构示意图多层前馈网络的适用范围大大超过原始网络,但其主要困难是中间的隐层不直接与外界连接,无法直接计算其误差。为解决这一问题,提出了反向传播算法。......
2023-06-16
相关推荐