针对这种情况,本节提出了使用加权重叠滤波的思想以克服上述缺点,以改进传统变换域自适应算法的收敛性能。令Et x=z,采用同普通LMS自适应滤波器相类似的方法可得WO-TLMS自适应滤波器权矢量的维纳解wopt和相应的最小均方误差εmin分别为式中,E t=QET=QOW。WO-TLMS中加权重叠矩阵对自适应算法的改善效果与WO-LMS一样,但采用不同的正交变换对系统性能的改善程度也会不同。......
2023-06-23
由第4章中内容可知,任何正交变换域ap在时域中都可以等效为一个FIR滤波器,与传统滤波器不同的是,在输入端不是原始信号的直接输入而是首先对它进行加权后再重叠,得到的结果作为滤波器的实际输入。将这种对信号的加权重叠预处理思想运用于以LMS为准则的自适应滤波算法中,提出加权重叠LMS自适应滤波算法(WO-LMS)。与LMS相比,它提高了收敛速度同时使稳态失调大为降低。
结合横向LMS滤波器结构,得到相应的WO-LMS系统如图9-9所示。
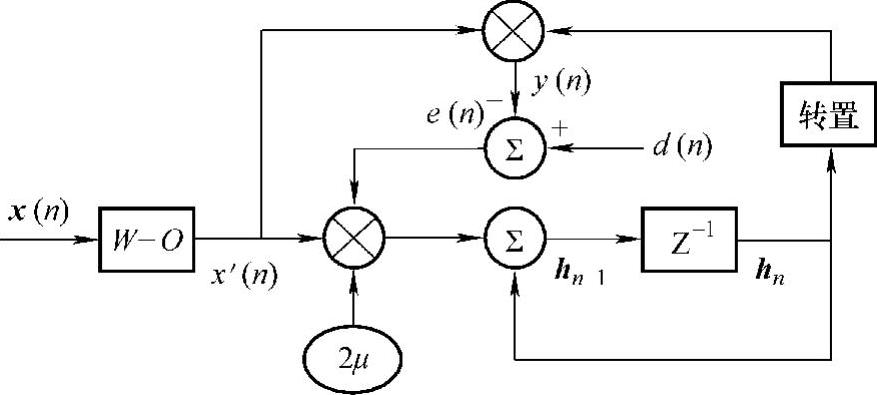
图9-9 WO-LMS自适应滤波器信号流图
图9-9中,x(n)=[x(n-N+1)…x(n-1)x(n)x(n+1)…x(n+N-1)]T是系统在n时刻的输入,N是系统权的个数。x′(n)是x(n)的加窗重叠处理。y(n)是系统在n时刻的输出,d(n)是期望响应,e(n)是n时刻的误差,h是系统冲击响应,μ是步长。由图9-9可以得到如下关系式:
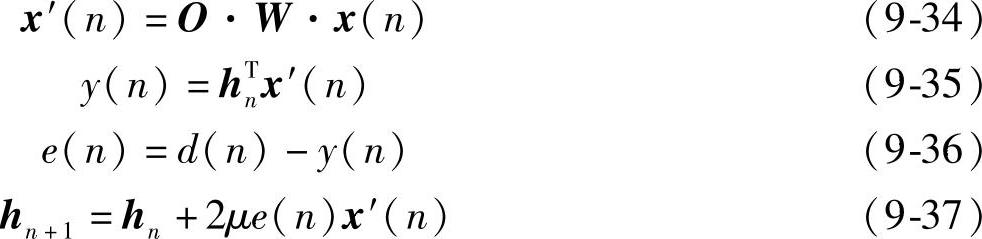
式中,O是重叠矩阵;W是加权矩阵,显然加权矩阵等于延迟窗C构成的对角阵。将式(9-34)分别代入到式(9-35)和式(9-37)中并整理得:
y(n)=(E·hn)T x(n) (9-38)
hn+1=hn+2μe(n)ET·x(n) (9-39)
O和W的乘积即为全相位转移矩阵E的转置,即:
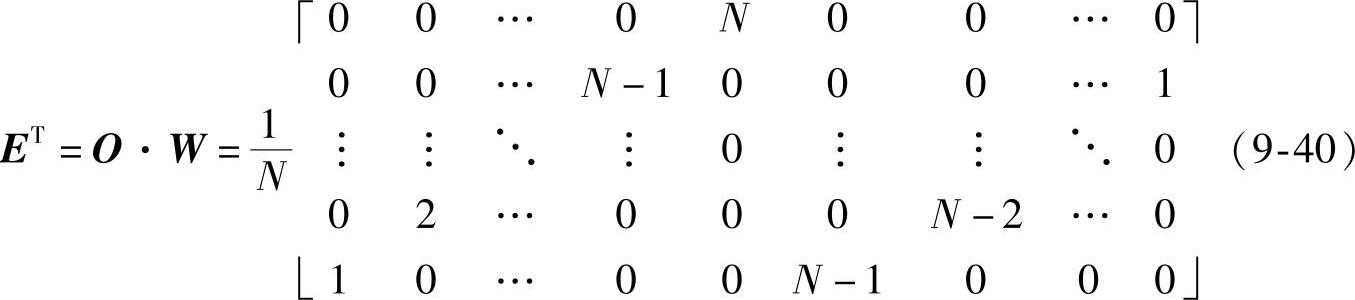
结合式(9-35)、式(9-36)和式(9-38),可求得均方误差为
E[e2(n)]=E[(d(n)-hTnETx(n))2] (9-41)
将式(9-41)展开整理得:
E [e2 (n)]=E [y2 (n)]-2 hTnETP+hTnETRE hn (9-42)
式中,P=E[d(n)x(n)];R=E[x(n)xT(n)]。上式对hn求偏导等于0,求出使均方误差最小的冲击响应h*满足:
ETREh*=ETP (9-43)
用响应误差向量Δhn=hn-h*代入式(9-42),并结合式(9-36)和式(9-38)得到:
hn+1=[I-2μ·ETx(n)xT(n)E](Δ hn+h*)+2μ·ETx(n)d(n)=[I-2μ·ETx(n)xT(n)E]Δ hn+h*+2μ·ET[x(n)d(n)-x(n)xT(n)E h*]⇒Δ hn+1=[I-2μ·ETx(n)xT(n)E]Δ hn+2μ·ET[x(n)d(n)-x(n)xT(n)E h*] (9-44)
式中,Δhn+1=hn+1-h*表示响应误差矢量的更新值。为了分析方便,假定Δh和x(n)相互独立。对式(9-44)两边取数学期望得到:
E[Δhn+1]=E{[I-2μ·ETx(n)xT(n)E]Δ hn}+2μ·E{ET[x(n)d(n)-x(n)xT(n)E h*]}=(I-2μ·ETE[x(n)xT(n)]E)E[Δ hn]+2μ·ETE[x(n)d(n)]-2μ·ETE[x(n)xT(n)]E h*=(I-2μ·ET RE)E[Δ hn]+2μ(ET P-ET RE h*) (9-45)
由式(9-43)可知式(9-45)的第二项等于0矩阵,所以又可以简化为
E[Δ hn+1]=(I-2μ·D)E[Δ hn] (9-46)
式中,D=ET RE。显然,D是Hermite型矩阵。由LMS收敛准则知,当步长满足下式时式(9-46)收敛:
0<μ<1/λmax (9-47)
式中,λmax是D的最大特征值。由矩阵理论可知:
tr(D)=tr(ET RE)≤tr(ET E)tr(R)(9-48)由全相位转移矩阵定义,可知:
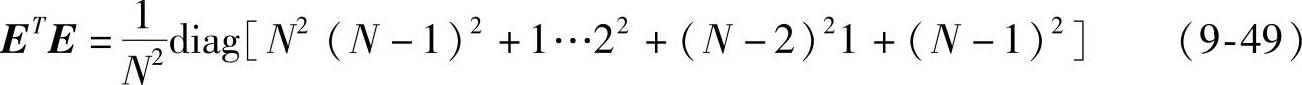
结合式(9-48)和式(9-49)得:

将式(9-50)和式(9-47)结合得:
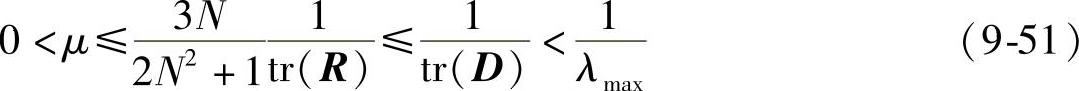
同理可以求出ap1sd对应自适应滤波算法收敛的步长范围。当N相当大时,进一步放小不等式得到3种步长的范围依次为(各种窗经过归一化处理):
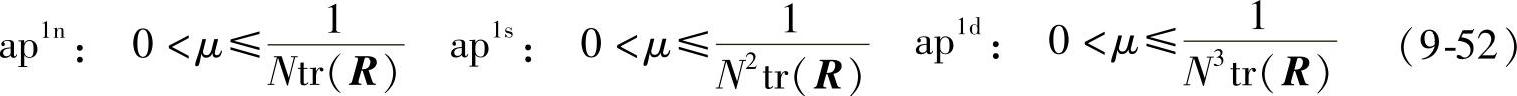
上面就是WO-LMS算法收敛的条件。
值得注意的是,LMS算法的收敛性能依赖输入信号的谱动态范围。谱动态范围越大的收敛性越差,越小则收敛性能越好。WO-LMS算法由于对输入信号进行了加权重叠处理,使算法的收敛性得到改善。
由上面的分析可知,加权重叠处理前后系统的收敛性能分别取决于相关矩阵Rxx和Rx′x′的特征值分布。令tr(M)与det(M)分别表示N阶方阵M的迹和行列式值,则其最大与最小特征值λmax、λmin有如下关系:
λmax≤tr(M)λmin≥det(M)N>2 (9-53)
这样,有

可以作为矩阵M谱动态范围的上限。利用上述结果由式(9-38)可知,

根据矩阵理论的一般知识,有
tr(ETRxxE)≤tr(ETE)tr(Rxx) (9-56)
对于ap1nsd的转移矩阵E具有“双对角”形状,对角线上的元素等于卷积窗C的对应元素。以N阶ap1n为例,令E=[E1,E2],其中:
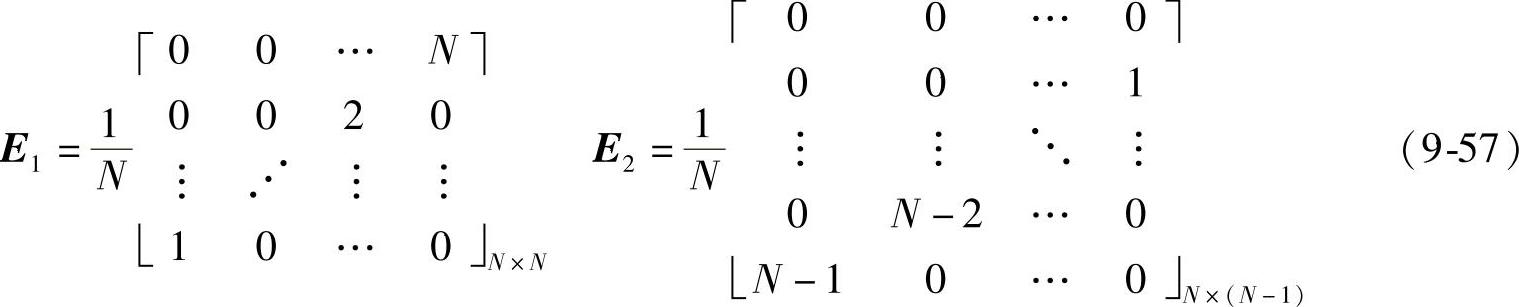
设矢量x(n)的前N个输入x1(n)=[x(n-N+1)…x(n-1)x(n)]T和后N-1个输入x2(n)=[x(n-1)x(n-2)…x(n-N+1)]T的自相关和互相关分别为r11、r22与r12、r21,则

按照LMS算法给出的充分条件,x1和x2的相关性很小即认为r2=r2T1≈0。所以
det(Rxx)≈det(r11)det(r22) (9-59)
加权重叠信号x′的自相关等于:

又由于r11、r22均为正定矩阵且E2为行线性相关,因此

所以,有
det(Rx′x′)=det(ET1 r11E1)=det(r11)det(ET1E1) (9-62)
由相关的定义可知,
det(ET1 E1)=[(N-1)!]2>Ndet(r22)⇒det(Rx′x′)≥Ndet(Rxx) (9-63)
结合上面各式可得,
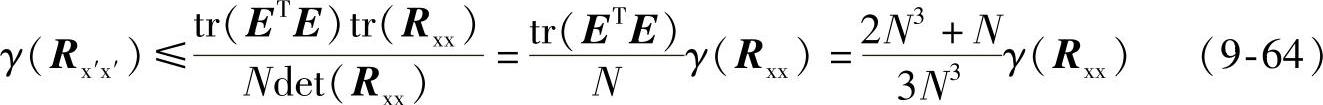
当N较大时,由式(9-64)可得以下关系:
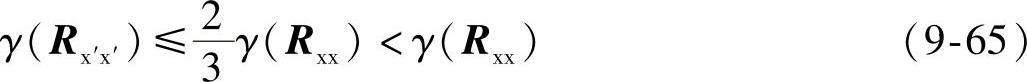
式(9-65)表明输入信号经过加权重叠处理后相关矩阵的特征值分散程度减小,因此提高了收敛速度。由式(9-52)又可看出由于步长减小,所以稳态误差也较小于LMS算法。上面对ap1n的情况进行了分析,对于ap1s结论仍然成立;对于ap1d将无法保证式(9-65)成立,因此收敛速度比LMS低但稳态误差比无窗和单窗系统都低。另一方面,滤波器阶数的大小和正交基的选择对W-O算法的改善程度都有影响,这将在下面的实验中得以证实。
有关全相位数字信号处理方法及MATLAB实现的文章

针对这种情况,本节提出了使用加权重叠滤波的思想以克服上述缺点,以改进传统变换域自适应算法的收敛性能。令Et x=z,采用同普通LMS自适应滤波器相类似的方法可得WO-TLMS自适应滤波器权矢量的维纳解wopt和相应的最小均方误差εmin分别为式中,E t=QET=QOW。WO-TLMS中加权重叠矩阵对自适应算法的改善效果与WO-LMS一样,但采用不同的正交变换对系统性能的改善程度也会不同。......
2023-06-23

按照自适应滤波系数矢量的变化与梯度矢量方向之间的关系,可写出LMS算法的公式如下:因为,所以这种瞬时估计法是无偏的。图9-6 自适应LMS算法信号流图由此可见,自适应LMS算法简单,它既不需要计算输入信号的相关函数,也不要求矩阵可逆。但是,由于LMS算法采用梯度矢量的瞬时估计值,它有较大的方差以致不能获得最优滤波性能。下面从收敛性、学习曲线和失调3个方面分析LMS算法的收敛性能。......
2023-06-23

图9-11为一个自适应辨识原理图。图9-12a是8阶自适应滤波器的WO-LMS和LMS算法50次实验的输入自相关分散程度曲线。从图中可见WO-LMS算法比LMS算法有较高的收敛性能,且改善程度随滤波器阶数增加而增大。所以,LMS算法收敛时,自适应滤波器的滤波系数等于被辨识的权矢量。图9-12 WO-LMS和LMS算法输入自相关矩阵的分散比较下面将给出在不同步长时,WO-LMS算法响应收敛曲线和LMS算法收敛曲线的比较。......
2023-06-23
为寻找更为理想的基窗函数,借助LMS算法思想提出了“基于LMS准则以apSW为模型的基窗函数设计方法”。图3-21 余弦基神经自适应网络图3-21 余弦基神经自适应网络图3-22 apSW基窗LMS设计算法按照流程图,设计截止频率为π/4的32阶低通apSW的窗函数F。......
2023-06-23

量子遗传算法是一种将遗传算法和量子计算相结合的概率优化方法,两者相互作用。量子遗传算法是一种将量子比特的概率幅用于染色体编码,用量子门的调整操作来实现染色体更新,以完成进化搜索的方法。量子遗传算法的流程如下:初始化种群Q,随机生成n个用量子比特编码的染色体。......
2023-06-29
一般来说,中文分词在具体的算法实现上分为三种:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。在中文搜索引擎中,目前基本上是这三种算法混合使用。2)基于统计的分词方法基于统计的分词方法也叫最大概率分词方法。作为中文分词基础的词库,新词补充和老词删除就是非常重要的工作。比如“测试”在“每台计算机在出厂前都要经过严格的测试”这句话中是典型的动词,而在“软件测试领域”中是一个名词。......
2023-07-02
DBSCAN通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于minPts个,则创建一个以p为核心对象的簇。DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并。当没有新的点添加到任何簇时,该过程结束。算法9.3DBSCAN算法输入:数据集D;给定点在邻域内成为核心对象的最小邻域点数:minPts;邻域半径:Eps;输出:簇集合。标记所有对象为unvisited。重复步骤~,直至没有标记为unvisited的对象。......
2023-06-21

1)BA网络算法初始设定m0个孤立节点。此算法来自于对分子网络中蛋白质组织结构的分析。研究发现,对于交互和规律的网络来说,高度连接的蛋白质连接被系统的抑制,然而在那些处于高度连接和稀少连接之间的蛋白质结构却没有被抑制。表3-1算法1表3-2算法23)中心分析中心性分析用来检测网络中的关键点以及对网络元素进行排序。......
2023-07-02
相关推荐